Capítulo 12 Minería de datos web
Gonzalo Barría49
Lecturas sugeridas
Calvo, E. (2015). Anatomía política de Twitter en Argentina. Tuiteando #Nisman. Buenos Aires: Capital Intelectual.
Steinert-Threlkeld, Z. (2018). Twitter as Data (Elements in Quantitative and Computational Methods for the Social Sciences). Cambridge: Cambridge University Press.
Los paquetes que necesitas instalar
tidyverse(Wickham 2019b),glue(Hester 2020),rvest(Wickham 2019a),rtweet(Kearney 2020).
12.1 Introducción
La información en Internet crece exponencialmente cada día. Si el problema de la ciencia política en el siglo XX fue la falta de datos para probar hipótesis, el siglo XXI presenta otro desafío: la información es abundante y está al alcance de la mano, pero hay que saber cómo recopilarla y analizarla. Esta enorme cantidad de datos está generalmente disponible pero de forma no estructurada, por lo que cuando te encuentres con la información tendrás dos retos principales: extraerla y luego clasificarla (es decir, dejarla como datos organizados (tidy)).
Una de las técnicas más utilizadas para extraer información de los sitios web es la técnica conocida como web scraping.
El web scraping se está convirtiendo en una técnica cada vez más popular en el análisis de datos debido a su versatilidad para tratar con diferentes sitios web. Como podemos ver en el siguiente gráfico, las búsquedas en Google del término “web scraping” han crecido constantemente año tras año desde 200:
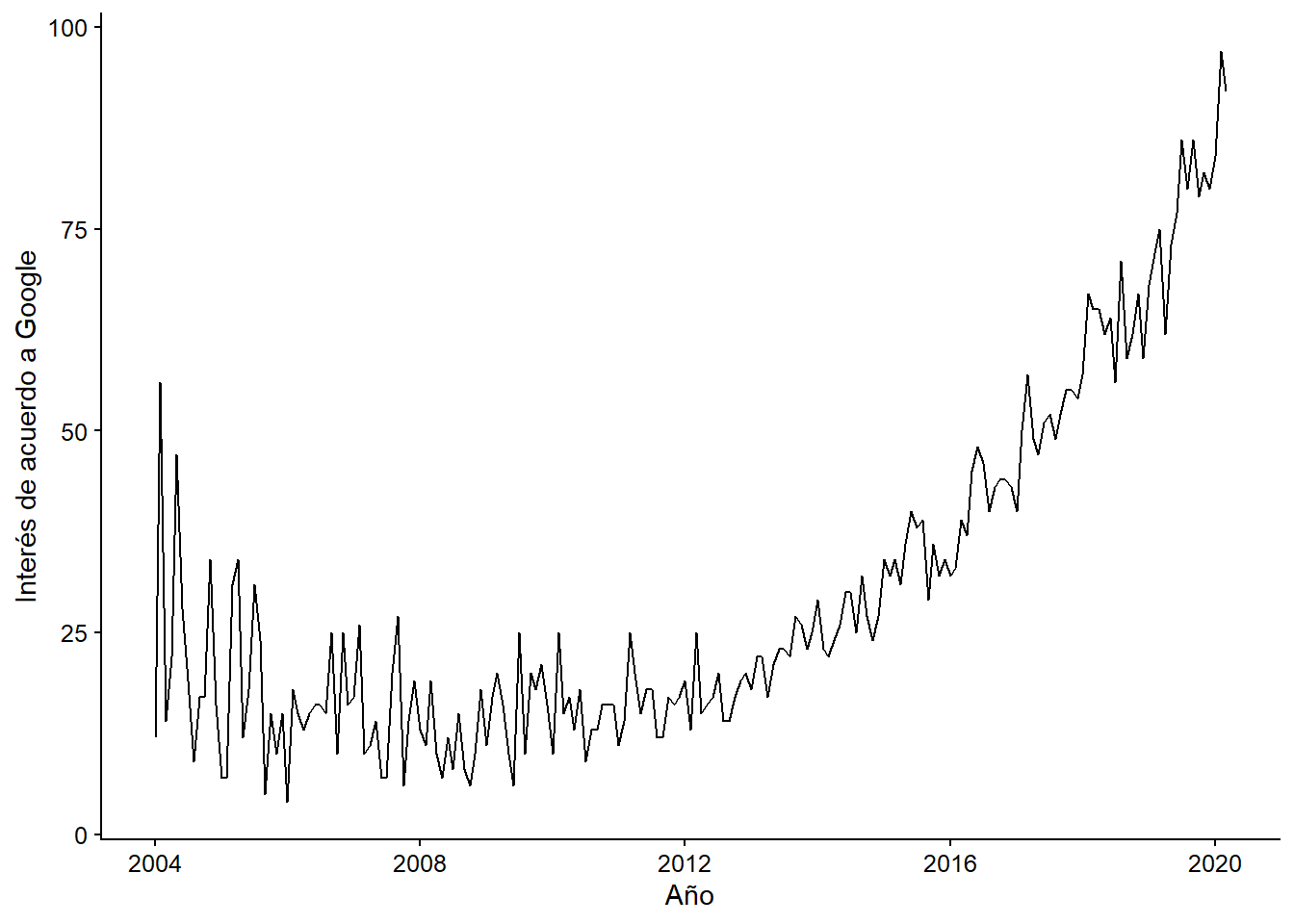
Figura 12.1: Búsquedas de ‘web scraping’ en Google
Esto consiste en obtener datos no muy estructurados (HTML) desde un sitio web, que usualmente luego transformamos a un formato estructurado con filas y columnas, con el que es más fácil trabajar. Nos permite obtener datos de fuentes no tradicionales (¡prácticamente cualquier página web!)
- La información que podemos obtener es la misma que podríamos hacer manualmente (copiar y pegar a un documento de Excel, por ejemplo), pero podemos automatizar tareas muy tediosas.
¿Para qué podríamos usar el web scraping? Como ejemplo práctico, vamos a realizar 2 simples ejercicios de extracción de datos. Pero antes de eso es bueno estar familiarizado con las fuentes de información y los múltiples usos que se le pueden dar a los datos extraídos. Algunas otras posibles aplicaciones para las que se puede usar el web scraping son:
Por ejemplo, pueden utilizarse para clasificar productos o servicios para crear motores de recomendación, para obtener datos de texto, como en la Wikipedia, para hacer sistemas basados en el Procesamiento del Lenguaje Natural.
Generar datos a partir de etiquetas de imágenes, de sitios web como Google, Flickr, etc. para entrenar modelos de clasificación de imágenes.
Consolidar los datos de las redes sociales: Facebook y Twitter, para realizar análisis de sentimientos u opiniones.
Extraer comentarios de usuarios y sitios de comercio electrónico como Alibaba, Amazon o Walmart.
12.2 Formas de hacer web scraping
Podemos raspar (scrape) los datos, es decir, obtenerlos, de diferentes maneras:
Copiar y pegar: obviamente esto debe ser hecho por un humano, es una manera lenta e ineficiente de obtener datos de la web.
Uso de APIs: API (por sus siglas en inglés) significa interfaz de programación de aplicaciones. Sitios web como Facebook, Twitter, LinkedIn, entre otros, ofrecen una API pública y/o privada, a la que se puede acceder mediante programación, para recuperar datos en el formato deseado. Una API es un conjunto de definiciones y protocolos utilizados para desarrollar e integrar programas informáticos de aplicación. En pocas palabras, es un código que indica a las aplicaciones cómo pueden comunicarse entre sí. Las API permiten que sus productos y servicios se comuniquen con otros, sin necesidad de saber cómo se implementan. Esto simplifica el desarrollo de aplicaciones y ahorra tiempo y dinero.
Análisis DOM: DOM significa Documento Objeto Modelo y es esencialmente una interfaz de plataforma que proporciona un conjunto estándar de objetos para representar documentos HTML y XML. El DOM permite el acceso dinámico a través de la programación para acceder, añadir y cambiar dinámicamente el contenido estructurado en documentos con lenguajes como JavaScript. A través de algunos programas es posible recuperar el contenido dinámico, o partes de sitios web generados por scripts de un cliente. Los objetos DOM modelan tanto la ventana del navegador como el historial, el documento o la página web, y todos los elementos que la propia página puede tener, como párrafos, divisiones, tablas, formularios y sus campos, etc. A través del DOM se puede acceder, mediante Javascript, a cualquiera de estos elementos, es decir, a sus correspondientes objetos para alterar sus propiedades o invocar sus métodos. Sin embargo, a través del DOM, cualquier elemento de la página está disponible para los programadores de Javascript, para modificarlos, borrarlos, crear nuevos elementos y colocarlos en la página.
12.2.1 Estándar de exclusión de robot
Antes de entrar en la práctica del web scraping tenemos que entender mejor qué es y cómo funciona el archivo robots.txt presente en la mayoría de los sitios web. Este archivo contiene el llamado estándar de exclusión de robot que es una serie de instrucciones especialmente dirigidas a los programas que buscan indexar el contenido de estas páginas (por ejemplo el bot de Google que “guarda” las nuevas páginas que se crean en Internet). Este método se utiliza para evitar que ciertos bots que analizan sitios de Internet añadan información “innecesaria” a los resultados de las búsquedas. Un archivo robots.txt en una página web funcionará como una petición para que ciertos bots ignoren archivos o directorios específicos en su búsqueda. Esto es importante cuando hablamos de web scraping ya que siempre es aconsejable revisar el archivo robots.txt de una página web antes de iniciar el scraping ya que puede incluir información que necesitaremos más adelante. Un ejemplo de cómo es uno de estos archivos se puede encontrar en el archivo robots.txt de Google (https://www.google.com/robots.txt).

Figura 12.2: Vistazo a los estándares de exclusión de Google
En esta imagen encontramos la expresión Usuario-agente: . Esto permite a todos los robots acceder a los archivos que se almacenan en el código principal de la página web ya que el comodín () significa “TODO.” A continuación vemos que los robots no pueden indexar o visitar páginas web del tipo /index.html?* o /grupos por ejemplo. Si encontramos la expresión Rechazar: / significa que se le niega el acceso a todos los bots (el comodín / se aplica automáticamente a todos los archivos almacenados en el directorio raíz del sitio web).
12.3 Web scraping en R
Iremos cargando los paquetes que necesitamos. Ya estás familiarizado con algunos de ellos como ggplot2, que es parte del tidyverse. El paquete rvest es el que nos permitirá hacer el scraping de datos con R. Es esencialmente una librería que nos permite traer y manipular datos de una página web, usando HTML y XML. Finalmente, el paquete glue está diseñado para hacer más fácil interpolar (pegar) datos en strings¨
library(tidyverse)
library(glue)
library(rvest)Para “leer” datos de diferentes sitios web necesitaremos la ayuda de una herramienta de código abierto (open source tool), un plugin llamado “selectorgadget.” Este se utiliza para extraer información de un sitio web. En este caso lo usaremos para seleccionar y resaltar las partes del sitio web que queremos extraer.
Se puede encontrar más información en este enlace y aquí
12.3.1 Ejemplo aplicado: los comunicados de prensa de la Organización de Estados Americanos (OEA)
Como primer ejemplo haremos un web scraping de un sitio estático. Es decir, un sitio web que tiene texto en HTML y que no cambia. Supongamos que estamos trabajando en un proyecto de diplomacia y relaciones internacionales en el que debemos sistematizar la información sobre la interacción entre los países de América Latina. Uno de los repositorios más útiles para iniciar este tipo de investigación es el sitio web de la Organización de Estados Americanos (OEA). Se puede encontrar en el siguiente link.
Este sitio ofrece información muy pertinente para los analistas de datos políticos, ya que se trata de datos no estructurados que permiten identificar, por ejemplo, las redes de países, las alianzas, las fuentes de conflicto y las cuestiones que los ministerios de relaciones exteriores consideran pertinentes.
Antes de comenzar con el web scraping en sí mismo analizaremos el archivo robots-txt del sitio web de la OEA.
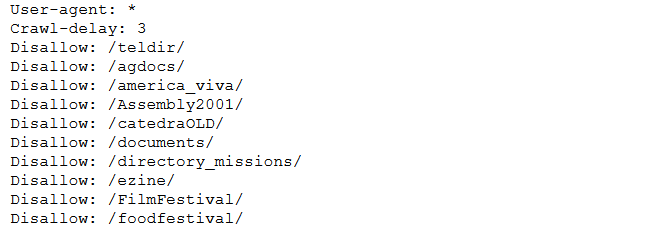
Figura 3.3: Vistazo al archivo robots.txt de la OEA
Encontramos que algunos directorios están prohibidos de ser indexados, pero todos los bots y usuarios están autorizados a visitar el sitio. Lo más importante es la expresión Crawl-delay: 3 que básicamente nos dice que por cada petición hecha por un robot es aconsejable esperar 3 segundos entre una consulta y otra para no saturar el sitio, lo que puede resultar en que te bloquee.
En este ejemplo en particular, queremos extraer los títulos de los comunicados de prensa que se encuentran en este sitio web. Para simplificar, se recomienda utilizar Google Chrome y la extensión Selector Gadget para este buscador.^[Se puede instalar desde este enlace. La extensión Selector Gadget también funciona en Firefox y en Safari (así como en otros navegadores), sólo tienes que arrastrar el marcador a tu barra de marcadores.
Primero cargamos la página como un objeto para que luego podamos leerla como un archivo html. En este caso queremos que los títulos de los comunicados de prensa de la Organización de Estados Americanos (OEA) para octubre de 2019
download_html(url = "https://www.oas.org/es/centro_noticias/
comunicados_prensa.asp?nMes=10&nAnio=2019",
file = "webs/comunicados_oea_10_2019.html")12.3.2 Caraga el html para trabajar con R
Una vez que descargamos los datos, los importamos en R usando read_html()
web_comunicados_10_2019 <- read_html("webs/comunicados_oea_10_2019.html",
encoding = "UTF-8")12.3.3 Extraer la información con html_nodes() + html_text()
A continuación, abrimos la página en Google Chrome donde lo primero que veremos es el sitio con las noticias. Allí hacemos clic en la extensión Chrome del Selector Gadget como se indica en la figura de abajo (es la pequeña lupa en la esquina superior derecha).
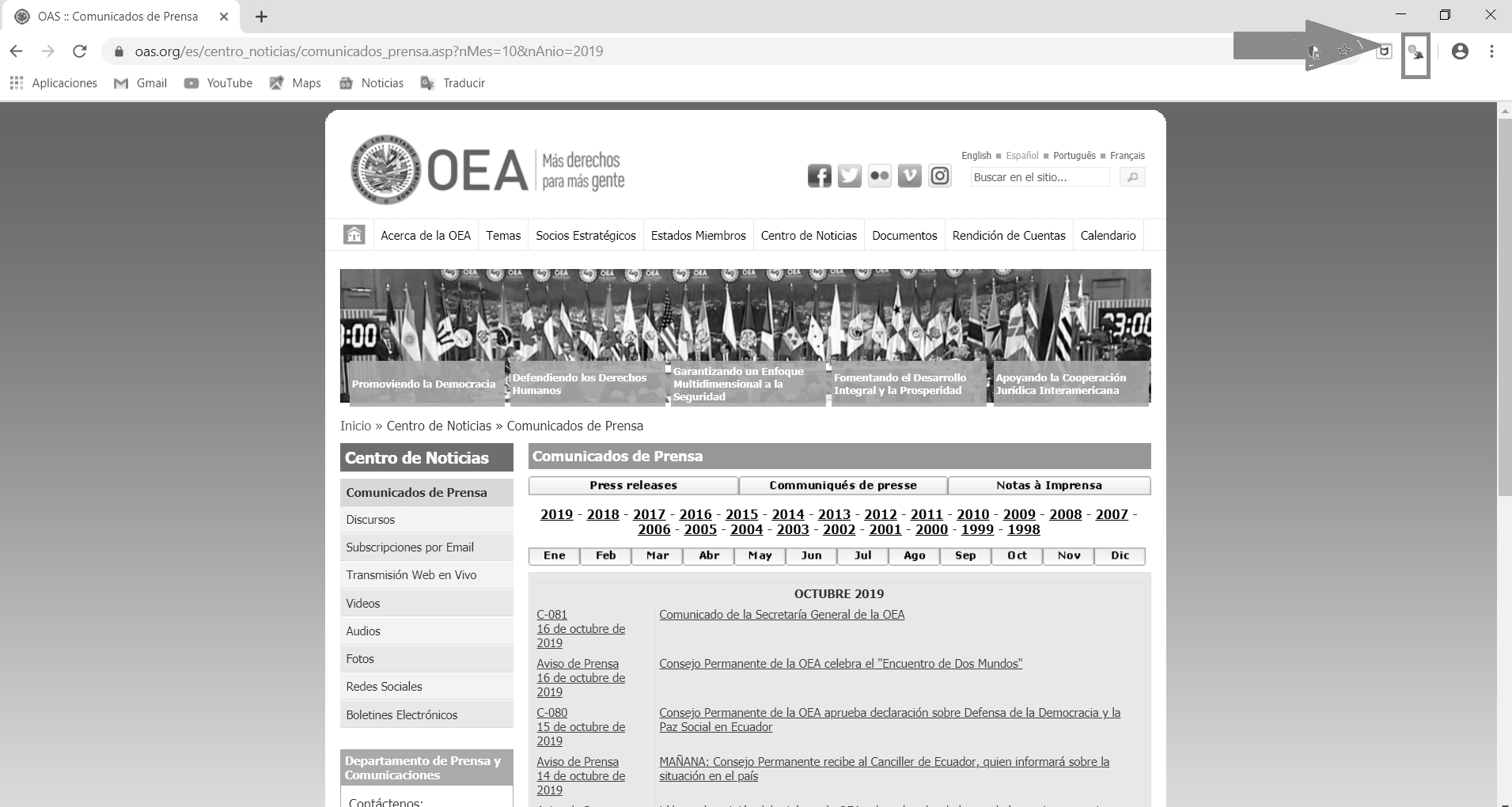
Figura 3.6: Pantallazo del sitio de los comunicados de prensa de la OEA
El primer paso es encontrar el selector de CSS que contiene nuestra información. En la mayoría de los casos sólo usaremos SelectorGadget. Empecemos con los títulos. Como podemos ver en la figura, seleccionamos la parte del sitio web que queremos extraer. En este caso queremos los títulos de los comunicados de prensa que después de ser seleccionados se destacan en amarillo. Observarán que al hacer clic en uno de ellos, aparece un mensaje “.itemmenulink” en el espacio vacío que hay en el Selector. Estos son los caracteres designados para los títulos en este sitio web
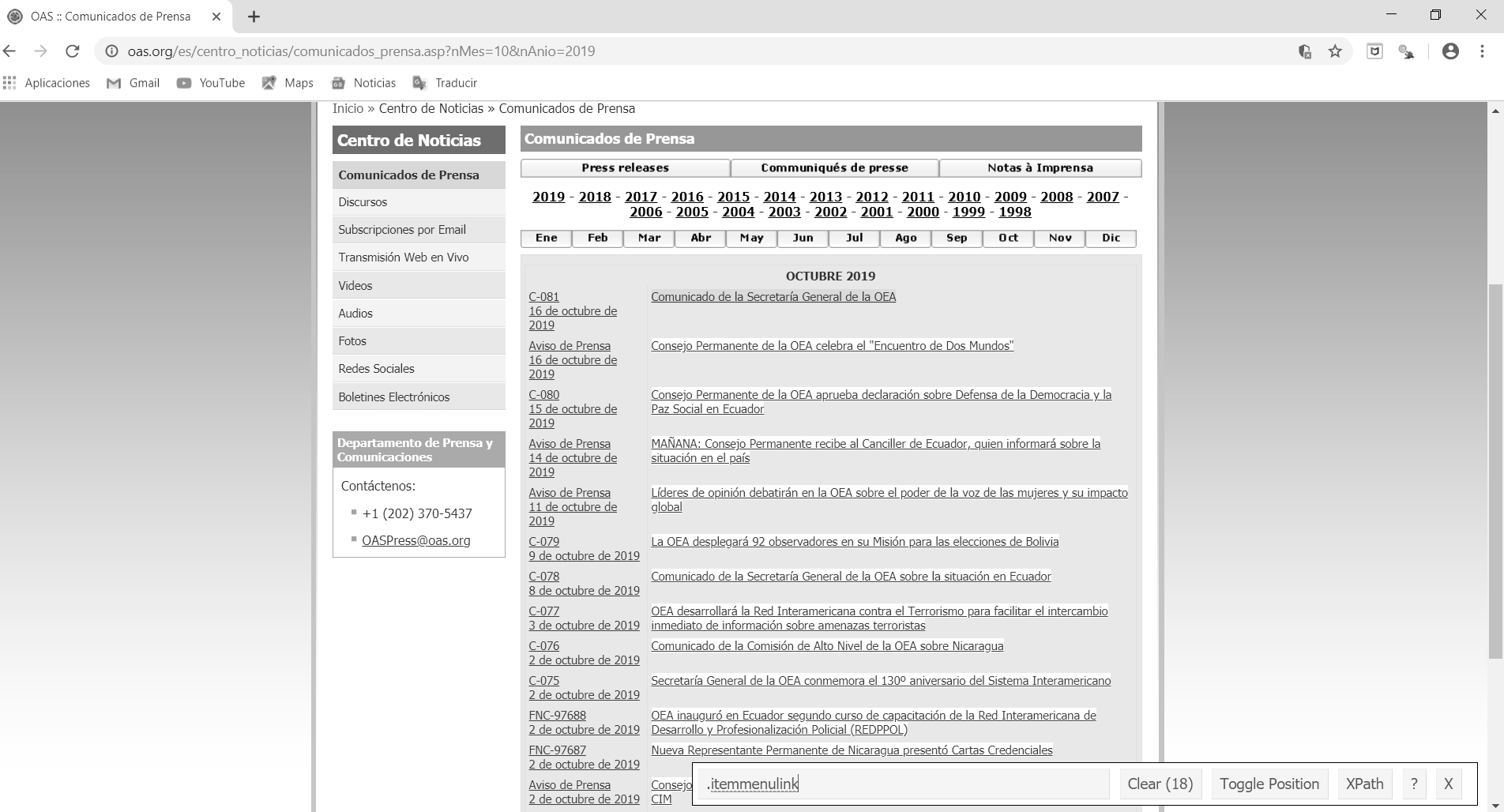
Figura 12.3: Títulos de los comunicados de prensa que queremos extraer
A continuación creamos un objeto para leer esta información como un objeto html en R. Lo llamaremos titulos_web_comunicados_10_2019. Dentro de la función html_nodes() añadimos el carácter “.itemmenulink” ya que representa los títulos según el selector.
titulos_web_comunicados_10_2019 <- web_comunicados_10_2019 %>%
html_nodes(".itemmenulink") %>%
html_text()Así es como obtuvimos los titulares de todo el sitio web.
Ahora revisaremos los primeros 10 resultados para ver cómo se clasificaron los datos. La idea más adelante sería transformar este objeto en un marco de datos. También podemos extraer el contenido de cada noticia, pero para ello necesitaríamos la URL en inglés (o en el idioma que prefieras) de cada comunicado de prensa.
head(titulos_web_comunicados_10_2019, n = 10)Para eliminar los enlaces de un elemento, en lugar de su texto, debemos sustituir html_text()por html_attr("href"):
links_web_comunicados_10_2019 <- web_comunicados_10_2019 %>%
html_nodes(".itemmenulink") %>%
html_attr("href") %>%
str_c("https://www.oas.org/es/centro_noticias/",.)
links_web_comunicados_10_2019
## [1] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-092/19"
## [2] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-091/19"
## [3] "https://www.oas.org/es/centro_noticias/fotonoticia.asp?sCodigo=FNC-97905"
## [4] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=D-023/19"
## [5] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=D-022/19"
## [6] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-090/19"
## [7] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=D-021/19"
## [8] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=D-020/19"
## [9] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-089/19"
## [10] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=AVI-209/19"
## [11] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=AVI-206/19"
## [12] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-087/19"
## [13] "https://www.oas.org/es/centro_noticias/fotonoticia.asp?sCodigo=FNC-97847"
## [14] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=D-019/19"
## [15] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=AVI-203/19"
## [16] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-086/19"
## [17] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=AVI-200/19"
## [18] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-085/19"
## [19] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-083/19"
## [20] "https://www.oas.org/es/centro_noticias/comunicado_prensa.asp?sCodigo=C-082/19"
## [ reached getOption("max.print") -- omitted 19 entries ]Ahora podemos crear un marco de datos (data frame) con toda la información:
df_web_comunicados_10_2019 <- tibble(
titulo = titulos_web_comunicados_10_2019,
link = links_web_comunicados_10_2019)
df_web_comunicados_10_2019
## # A tibble: 39 x 2
## titulo link
## <chr> <chr>
## 1 Ministros de Seguridad de las Amér~ https://www.oas.org/es/centro_not~
## 2 La SecretarÃa General de la OEA in~ https://www.oas.org/es/centro_not~
## 3 El Salvador será sede de la VIII R~ https://www.oas.org/es/centro_not~
## # ... with 36 more rowsEjercicio 12A. Consigue la fecha de cada comunicado de prensa de la OEA para octubre de 2019. Llama al vector “web_date_releases_10_2019.”
Ejercicio 12B. Consigue los títulos de las noticias de la página web de la revista The Economist como su sección internacional: https://www.economist.com/international/?page=1
12.3.4 Iteraciones
Las iteraciones nos permiten repetir la misma operación para un conjunto de elementos. Analicemos la sintaxis en el siguiente ejemplo:
print(10)[1] 10
walk(.x = 1:10,
.f = ~ {
print(.x)
})[1] 1 [1] 2 [1] 3 [1] 4 [1] 5 [1] 6 [1] 7 [1] 8 [1] 9 [1] 10
Podríamos descargar varias páginas del sitio web de la OEA con una iteración. Por ejemplo, descarguemos los comunicados de prensa de todos los meses de 2016 a 2018. Para ello, utilizamos la función cross_df() para crear un data.frame que contiene todas las combinaciones posibles entre meses y años:
iteration_df <- cross_df(list(month = 1:12,year = 2016:2018))Entonces, usamos la función walk2() que recibirá 2 argumentos que se iterarán, los meses y los años.
walk2(.x = iteration_df$month,
.y = iteration_df$year,
.f = ~ {
Sys.sleep(2) # stops
download_html(
url = glue("https://www.oas.org/es/centro_noticias/
comunicados_prensa.asp?nMes={.x}&nAnio={.y}"),
file = glue("webs/comunicados_oea_{.x}_{.y}.html"))
})Nuestros próximos pasos te mostrarán cómo procesar estos sitios web (en este caso haremos 37 URL, pero podrían ser muchos más) para crear una base de datos único. Utilizaremos funciones e iteraciones personalizadas en el proceso.
12.3.5 Funciones personalizadas (recetas)
Lo que hicimos hasta ahora para obtener nuestro marco de datos con información del sitio web de la OEA puede resumirse en los siguientes pasos:
Descargar el sitio
Sube el html a la ‘R’
Extraer los vectores para el título y el enlace usando selectores
Crear el marco de datos con estos vectores
Esto puede ser pensado como una “receta,” que debería funcionar para cualquier archivo. Por lo tanto, lo crearemos como una función personalizada para que trabajes con ella:
f_procesar_sitio <- function(file){
web <- read_html(file, encoding = "UTF-8")
titulos <- web %>%
html_nodes(".itemmenulink") %>%
html_text()
links <- web %>%
html_nodes(".itemmenulink") %>%
html_attr("href") %>%
str_c("https://www.oas.org/es/centro_noticias/",.)
df_info <- tibble(
titulo = titulos,
link = links
)
return(df_info) # what returns/delivers the function
}Ahora la función toma cualquier archivo como argumento y nos da lo que esperamos:
f_procesar_sitio(file = "webs/comunicados_oea_10_2016.html")
## # A tibble: 24 x 2
## titulo link
## <chr> <chr>
## 1 "Asamblea General Extraordinaria de~ https://www.oas.org/es/centro_not~
## 2 "ATENCIÃ\u0093N - ACTUALIZA FECHA Y~ https://www.oas.org/es/centro_not~
## 3 "La OEA y la UNESCO buscan reducir ~ https://www.oas.org/es/centro_not~
## # ... with 21 more rowsAsí, podemos iterar esta función en nuestros 37 archivos para crear una base de datos completo. En este caso no usaremos walk(), sino map_dfr() –esta función espera que cada iteración devuelva un marco de datos, y (debajo) los pega en orden con bind_rows().
archivos <- list.files("webs/", full.names = T)
archivos
## [1] "webs/comunicados_oea_1_2016.html"
## [2] "webs/comunicados_oea_1_2017.html"
## [3] "webs/comunicados_oea_1_2018.html"
## [4] "webs/comunicados_oea_10_2016.html"
## [5] "webs/comunicados_oea_10_2017.html"
## [6] "webs/comunicados_oea_10_2018.html"
## [7] "webs/comunicados_oea_10_2019.html"
## [8] "webs/comunicados_oea_11_2016.html"
## [9] "webs/comunicados_oea_11_2017.html"
## [10] "webs/comunicados_oea_11_2018.html"
## [11] "webs/comunicados_oea_12_2016.html"
## [12] "webs/comunicados_oea_12_2017.html"
## [13] "webs/comunicados_oea_12_2018.html"
## [14] "webs/comunicados_oea_2_2016.html"
## [15] "webs/comunicados_oea_2_2017.html"
## [16] "webs/comunicados_oea_2_2018.html"
## [17] "webs/comunicados_oea_3_2016.html"
## [18] "webs/comunicados_oea_3_2017.html"
## [19] "webs/comunicados_oea_3_2018.html"
## [20] "webs/comunicados_oea_4_2016.html"
## [ reached getOption("max.print") -- omitted 54 entries ]
df_web_comunicados_2016_2018 <- map_dfr(.x = archivos,
.f = ~ {
f_procesar_sitio(.x)
})
df_web_comunicados_2016_2018
## # A tibble: 1,397 x 2
## titulo link
## <chr> <chr>
## 1 "Misión Especial de la OEA llegarÃ~ https://www.oas.org/es/centro_not~
## 2 "OEA enviará Misión Especial a Ha~ https://www.oas.org/es/centro_not~
## 3 "ATENCIÃ\u0093N CAMBIO DE HORA: Con~ https://www.oas.org/es/centro_not~
## # ... with 1,394 more rows12.4 Usando APIs y extrayendo datos de Twitter
Twitter es una red social fundada en 2006 que permite a los usuarios interactuar entre sí enviando mensajes de no más de 280 caracteres. Es ampliamente usada por servicios públicos y por políticos especialmente en las épocas de campaña electoral. Con las nuevas técnicas de análisis de datos el estudio de la interacción de los usuarios en twitter se ha vuelto muy importante por ejemplo para medir los temas sobre los que está hablando la gente (trending topics) y sobre si las opiniones sobre una persona o tema son positivas o negativas. Por ejemplo Ernesto Calvo en su libro Anatomía Política de Twitter en Argentina: Tuiteando #NISMAN en el que identifica a través del estudio de los tweets sobre las causas de la muerte del ex fiscal Alberto Nisman que reflejaban (y estaban muy correlacionados con) las divisiones políticas de la oposición del gobiernon. A partir del caso Nisman, Ernesto Calvo analiza los tweets de los usuarios argentinos y muestra que la polarización mezcla política, algoritmos y smartphones.
Si has leído la sección anterior, ya conoces los paquetes R que se utilizarán en esta sección del libro. Para hacer la extracción de datos de Twitter la mejor opción en mano es Rtweet, que permite acceder gratuitamente al API de Twitter para descargar información de los usuarios, temas de tendencias y hashtags. Para extraer datos de Twitter con R se recomienda consultar Twitter as Data, que contiene algunas rutinas estandarizadas para descargar datos de esta plataforma.
12.4.1 Algunos antecedentes en APIs
La interfaz de programación de aplicaciones Application Program Interfaces (APIs en inglés) son un set de protocolos y funciones que gobiernan ciertas interacciones entre aplicaciones web y usuarios.
las APIs son similares a los navegadores web pero cumplen diferentes propósitos:
-Navegadores web reproducen contenido de los browsers
-Las APIs permiten manipular y organizador datosPara que las APIs públicas sean utilizadas muchos sitios solo permiten a usuarios autorizados (por ejemplo aquellos que tienen una cuenta en la plataforma). Este es el caso para Twitter, Facebook, Instagram and Github.
Si bien estas APIs son ampliamente conocidas no está demás mencionar algunas creadas por la misma comunidad de R especializada en datos políticos. Por ejemplo el paquete lobbyR creado por Daniel Alcatruz50 que permite cargar y estructurar datos desde la API lobby que se encuentra en la plataforma de Ley de Lobby implementada para el Gobierno de Chile, que permite realizar consultas por ejemplo sobre audiencias en determinados servicios públicos y organismos del estado como el congreso y los municipios. Otro paquete que es necesario mencionar es inegiR creado por Eduardo Flores que permite interactuar con la API del INEGI (Instituto Nacional de Estadística y Geografía de México) para realizar consultas específicas.
12.4.2 Extraer los datos
Lo primero es no depender de la API oficial de Twitter, y por lo tanto deberías tener tu propia cuenta de Twitter que puedes crear en este link.
Luego procedes a cargar el paquete rtweet que te permitirá extraer datos de Twitter. Te mostraremos esta rutina y extraeremos datos de diferentes usuarios y hashtags.
library(rtweet)Por ejemplo podemos obtener los IDs de las cuentas que sigue la ONU en español. Por defecto la función te muestra hasta 5000 usuarios.
## Obtener los ID que son seguidos por la cuenta de la ONU en español
friends_ONU_es <- get_friends("ONU_es")Para saber más información de estos usuarios utilizamos la lookup_users()
info_friends_ONU_es <- lookup_users(friends_ONU_es$user_id)Podemos obtener información de los seguidores también mediante la función get_followers(). Como la cuenta de twitter de ONU en español tiene más de un millón de seguidores, es más comodo hacer un anáisis de una porción de ellos. Para obtener todos los IDs de usuarios que siguen a @ONU_es, solo necesitas 2 cosas:
- Una conexión estable a Internet
- Tiempo - aproximadamente cinco días y medio
followers_ONU_es <- get_followers("ONU_es", n = 200,
retryonratelimit = TRUE)Aquí obtenemos la información de los usuarios que siguen la cuenta @ONU_es
info_followers_ONU_es<-lookup_users(followers_ONU_es$user_id)12.4.2.1 Buscando tweets especificos
Ahora estamos listos para buscar tweets recientes. Busquemos por ejemplo todos los tweets que lleven el hashtag “#Piñera,” en alusión al presidente chileno. Recordemos que un hashtag es una etiqueta que corresponde a una palabra antecedida por el símbolo “#.” Esta es utilizada principalmente para encontrar tweets con contenido similar, ya que el fin es que tanto el sistema como el usuario la identifiquen de forma rápida. Utilizaremos la función rtweet::search_tweets(). Esta función requiere los siguientes argumentos
`q`: la palabra que quieres buscar
`n`: el número de tweets máximos que quieres extraer. Puedes pedir un máximo de 18.000 tweets cada 15 minutos.Tip: Para ver otros argumentos de la función puedes usar el documento de ayuda
?search_tweetsUn aspecto importante que tenemos que aclarar con respecto a las consultas que le hacemos a la API de Twitter es que los resultados obtenidos no podrán reproducir completamente, estos cambiarán, ya que la versión gratuita de Twitter nos permite hacer consultas en un periodo terminado de tiempo en el pasado (por ejemplo una semana) por lo que los resultados de las consultas cambiarán con el tiempo. Si te interesa una cierta agenda o hashtag, un buen consejo es descargarla regularmente y guardarla en un disco duro. No podrás volver a ellas en el futuro.
# Buscar 500 tweets con el hashtag #piñera
pinera_tweets <- search_tweets(q = "#piñera",
n = 1000)
# Veamos las tres primeras observaciones
head(pinera_tweets, n = 3)
## # A tibble: 3 x 90
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 119113~ 13864069~ 2021-04-25 19:49:14 elmentalis~ @elm~ Twitt~
## 2 121023~ 13864061~ 2021-04-25 19:45:56 Maran39 #lar~ Twitt~
## 3 183273~ 13864058~ 2021-04-25 19:44:57 niviaoltra #lar~ Twitt~
## # ... with 84 more variablesPara obtener información de los usuarios que están emitiendo tweets sobre #piñera en el momento que estamos escribiendo este capitulo.
lookup_users(pinera_tweets$user_id)
## # A tibble: 814 x 90
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 119113~ 13864069~ 2021-04-25 19:49:14 elmentalis~ "@el~ Twitt~
## 2 121023~ 13864061~ 2021-04-25 19:45:56 Maran39 "#la~ Twitt~
## 3 183273~ 13864065~ 2021-04-25 19:47:34 niviaoltra "#Cu~ Twitt~
## # ... with 811 more rows, and 84 more variablesLas consultas de tweets pueden hacerse de varias maneras dependiendo en los que estas buscando:
12.4.3 Buscar una palabra clave
query_1 <- search_tweets(q = "piñera", n = 20)12.4.4 Buscar una frase
query_2 <- search_tweets(q = "piñera economia", n = 20)12.4.4.1 Buscar múltiples palabras claves
query_3 <- search_tweets(q = "piñera AND bachelet", n = 20)Por defecto search_tweets() retorna 100 tweets. Para retornar más el n debe ser mayor, esto se hace con n =.
Ejercicio 12C. En lugar de usar AND, usa OR entre los diferentes términos de búsqueda. Ambas búsquedas devolverán tweets muy diferentes.
12.4.4.2 Busca cualquier mención de una lista de palabras
query_4 <- search_tweets("bolsonaro OR piñera OR macri", n = 20)Ejercicio 12D. Buscar tweets en español que no sean retweets
12.4.4.3 Especifica el lenguaje de los tweets y excluye los retweets
query_5 <- search_tweets("piñera", lang = "es", include_rts = FALSE, n=20)12.4.5 Descargando características relacionadas con los usuarios de Twitter
12.4.5.1 Retweets
Un retweet es cuando tú o alguien más comparte un tweet para que tus seguidores puedan verlo. Es similar a la característica de “compartir” en Facebook. Hagamos la misma rutina de antes pero esta vez ignorando los retweets. Lo hacemos con el argumento include_rts definido como FALSE. Entonces podemos obtener tweets y retweets en un marco de datos separado
Nota: La opción
include_rts =es muy útil si estás estudiando los patrones de viralización de ciertos hashtags.
# Look for 500 tweets with the hashtag #piñera, but ignore retweets
pinera_tweets <- search_tweets("#piñera",
n = 500,
include_rts = FALSE)
# See the first two columns
head(pinera_tweets, n = 2)
## # A tibble: 2 x 90
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 136622~ 13864054~ 2021-04-25 19:43:03 DiputadoMo~ "Cua~ Twitt~
## 2 137688~ 13864044~ 2021-04-25 19:39:17 mamele8601~ "Vot~ Twitt~
## # ... with 84 more variablesAhora veamos quién está twiteando sobre el hashtag “#piñera”
# Look at the column with the names - top 6
head(pinera_tweets$screen_name)
## [1] "DiputadoMoraga" "mamele86019606" "mamele86019606" "mamele86019606"
## [5] "mamele86019606" "mamele86019606"
unique(pinera_tweets$screen_name)
## [1] "DiputadoMoraga" "mamele86019606" "luisriverosg"
## [4] "PolyTuteleers" "ocho_gatos" "ciudadanovidela"
## [7] "ivanazarapa" "ClaudiaTejias" "AAlyedi"
## [10] "cacolinux_" "El_Machuca_ckai" "Rodolfo_Lopez_E"
## [13] "ivan1671" "AlejandroSig" "CondorGolf"
## [16] "Yomimiyo1" "210_pau" "rodrigorrpp"
## [19] "pollipesenti" "alesiskalpo"
## [ reached getOption("max.print") -- omitted 294 entries ]También podemos usar la función search_users() para explorar qué usuarios están twiteando usando un hashtag particular. Esta función extrae un data.frame de los usuarios e información sobre sus cuentas.
# Which users are tweeting about #piñera?
users <- search_users("#piñera",
n = 500)
# see the first 2 users (the data frame is large)
head(users, n = 2)
## # A tibble: 2 x 90
## user_id status_id created_at screen_name text source
## <chr> <chr> <dttm> <chr> <chr> <chr>
## 1 201853~ 11916828~ 2019-11-05 11:45:16 Plaid_Pine~ "Of ~ Twitt~
## 2 947001~ 11362572~ 2019-06-05 13:03:23 robbiepine~ "@PL~ Twitt~
## # ... with 84 more variablesAprendamos más sobre estas personas. ¿De dónde son? Como vemos, hay 304 lugares únicos por lo que el gráfico que usamos para trazar la información no es addecuado para visualizarlo.
# How many places are represented?
length(unique(users$location))
## [1] 219
## [1] 304
users %>%
ggplot(aes(location)) +
geom_bar() +
coord_flip() +
labs(x = "Frecuencia",
y = "Ubicación",
title = "Cuentas de Twitter - Ubicaciones únicas")
Ordenemos por frecuencia las ubicaciones más nombradas y las trazamos. Para ello utilizamos top_n() que extraerá las localizaciones con al menos 20 usuarios asociados a ella
users %>%
count(location, sort = TRUE) %>%
mutate(location = reorder(location, n)) %>%
top_n(20) %>%
ggplot(aes(x = location, y = n)) +
geom_col() +
coord_flip() +
labs(x = "Frecuencia",
y = "Ubicación",
title = "¿De dónde son estas cuentas de Twitter? Ubicaciones únicas")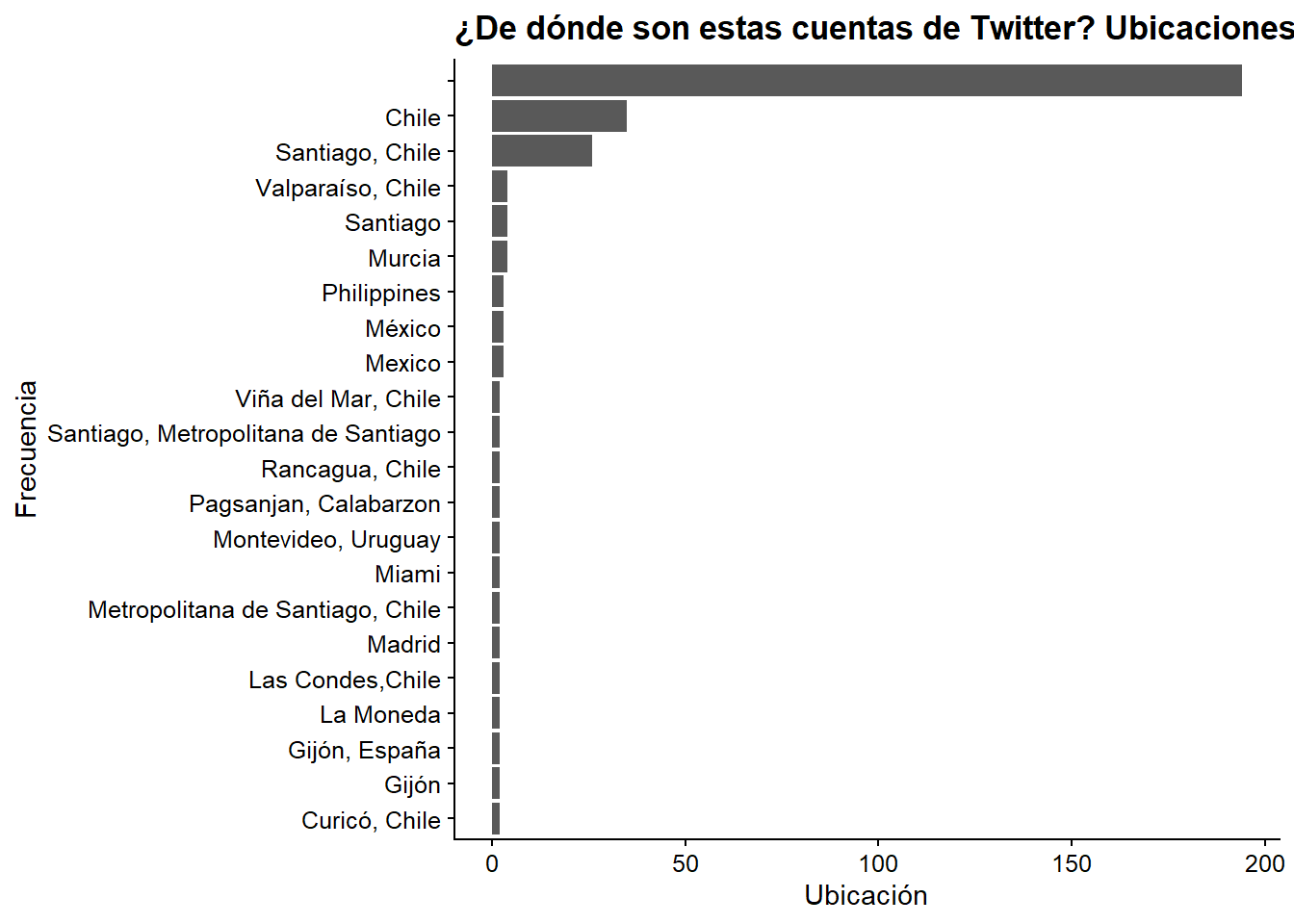
Es mejor si quitamos los NAs para ver los lugares más claramente. En general, la geolocalización en Twitter es bastante mediocre porque es voluntaria y pocas personas la tienen activada en sus teléfonos móviles. Así que lo que vemos es gente que quiere que sepamos su ubicación, lo que significa que hay un sesgo en estos resultados.
users %>%
count(location, sort = T) %>%
mutate(location = reorder(location,n)) %>%
na.omit() %>% filter(location != "") %>%
top_n(20) %>%
ggplot(aes(x = location,y = n)) +
geom_col() +
coord_flip() +
labs(x = "Ubicación",
y = "Frecuencia",
title = "Usuarios de Twitter - Ubicaciones únicas")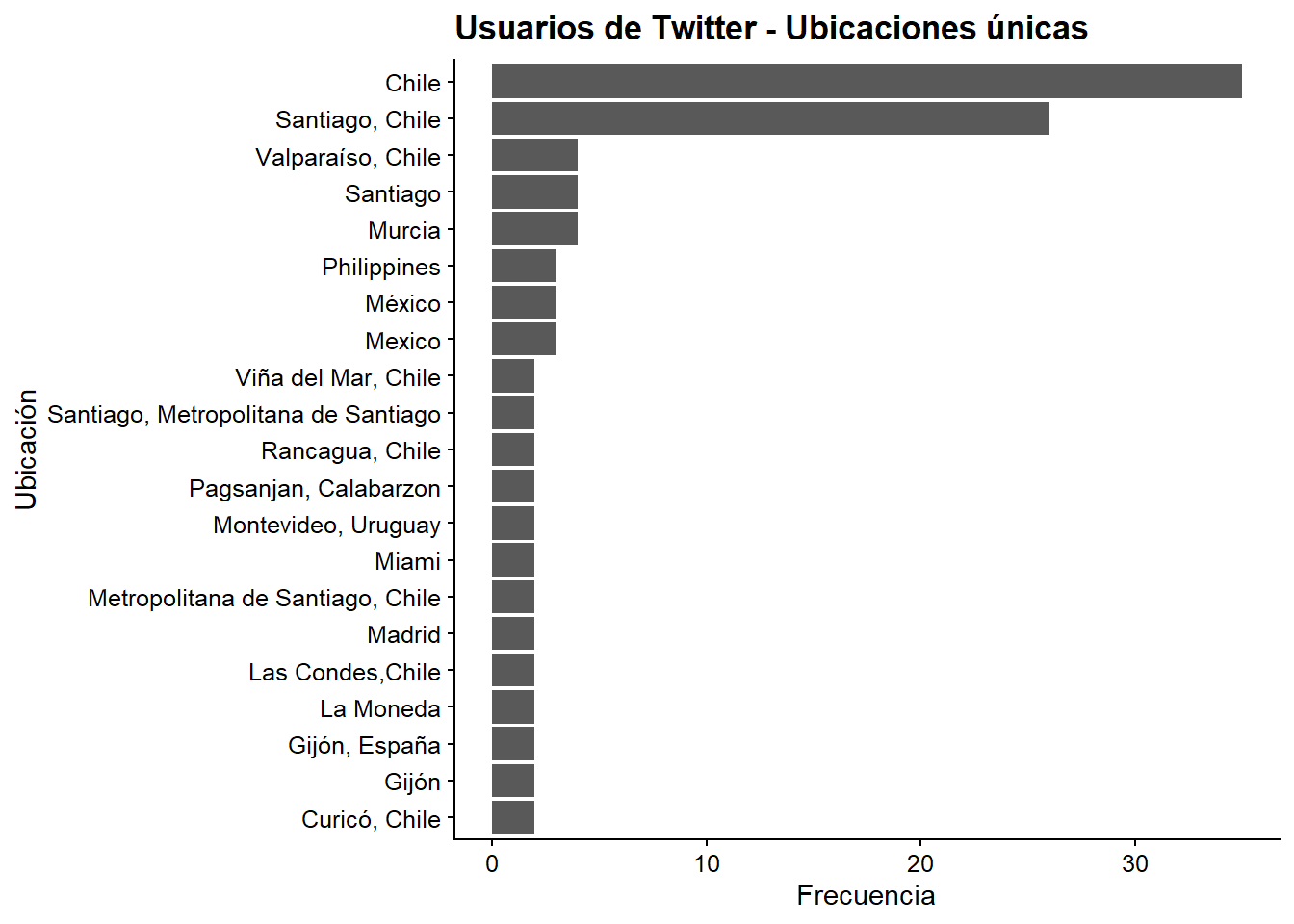
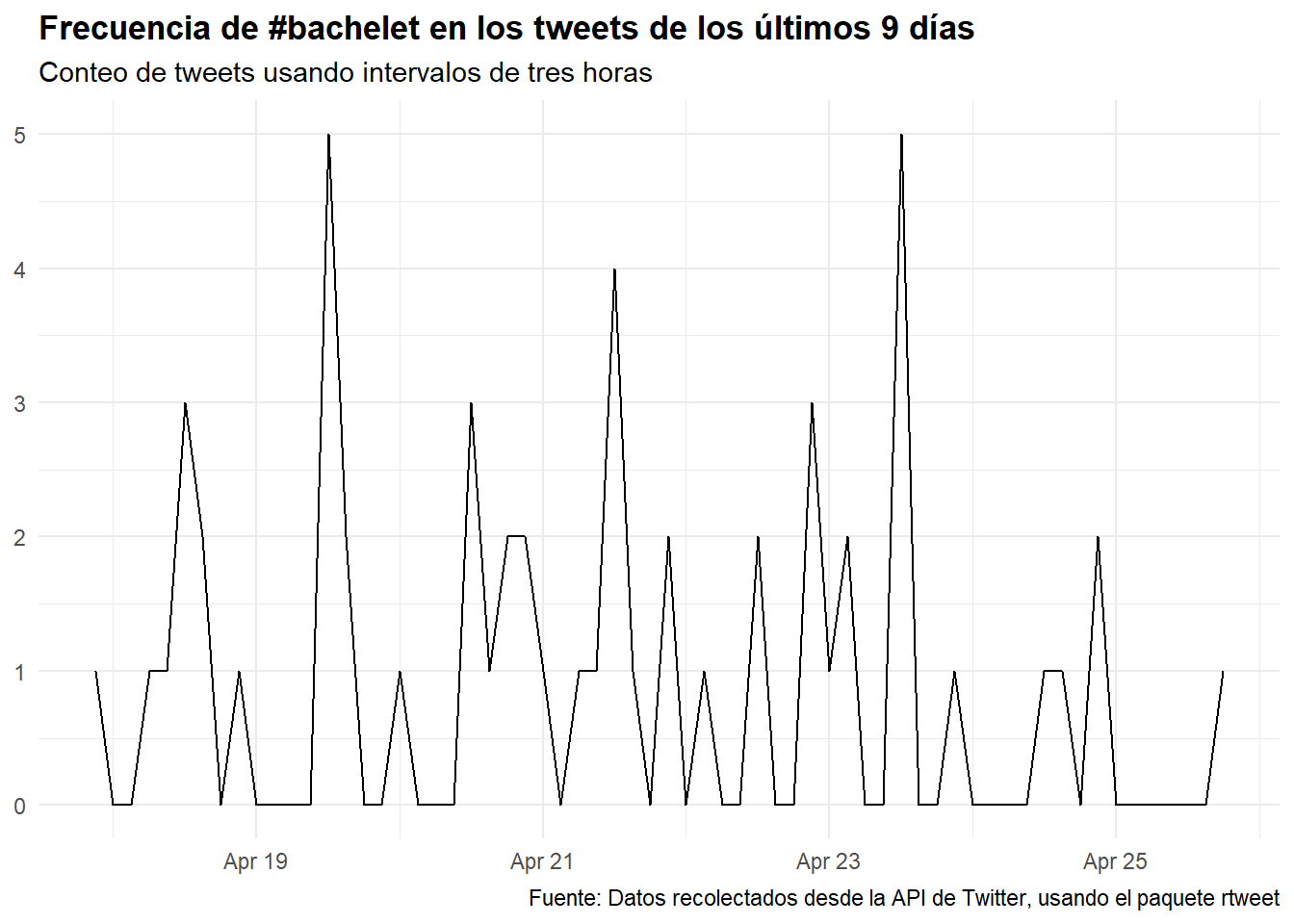
Finalmente repetimos el ejercicio usando hashtags que se refieren a Michelle Bachelet, la ex presidenta de Chile:
## Buscar tweets que usen el hashtag #bachelet
rt <- search_tweets(
"#bachelet", n = 600, include_rts = FALSE
)¿Cómo ha sido la tendencia temporal de este hashtag en los últimos días?
## Graficar una serie de tiempo de tweets
rt %>%
ts_plot("3 hours") +
ggplot2::theme_minimal() +
ggplot2::theme(plot.title = ggplot2::element_text(face = "bold")) +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frecuencia de #bachelet en los tweets de los últimos 9 días",
subtitle = "Conteo de tweets usando intervalos de tres horas",
caption = "Fuente: Datos recolectados desde la API de Twitter, usando el paquete rtweet"
)
Esperamos que este capítulo haya sido útil. En el Capítulo 13 te mostraremos cómo explorar más a fondo los datos de Twitter una vez que los hayas descargado.