Capítulo 3 Visualización de datos
Soledad Araya11
Lecturas sugeridas
Henshaw, A. L., & Meinke, S. R. (2018). Data analysis and data visualization as active learning in political science. Journal of Political Science Education, 14(4), 423-439.
Kastellec, J. P., & Leoni, E. L. (2007). Using graphs instead of tables in political science. Perspectives on Politics, 5(4), 755-771.
Tufte, E. R. (2006). Beautiful evidence. Graphics Press.
Los paquetes que necesitas instalar
tidyverse(Wickham 2019b),paqueteadp(Urdinez and Cruz 2020),ggrepel(Slowikowski 2020).
3.1 ¿Por qué visualizar mis datos?
Ya has aprendido a usar los comandos de Tidyverse, y probablemente quieras sumergirte en el mundo de los gráficos, y aplicar todo lo que has aprendido a tu propios datos. Con tidyverse y ggplot2, la visualización de datos se convierte en una tarea fácil, pero hay algunos pasos que debes seguir antes de escribir tu código. Por ejemplo, conocer tus variables. ¿Son variables continuas o categóricas? Cuando son categóricas, ¿tienen dos o más niveles? Además, esos niveles, ¿están en orden o no? Estas no son las únicas preguntas que tienes que considerar. Parece una tarea fácil, pero si no consideras este paso en tu trabajo con ggplot2 las cosas pueden ponerse feas bastante rápido. Se pueden encontrar ejemplos divertidos de esto en accidental aRt.
Una pregunta rápida: ¿Por qué representar nuestros datos gráficamente?
En primer lugar, sé que muchos de nosotros estamos interesados en representar nuestros datos gráficamente porque es una forma atractiva de hacerlo. Sin embargo, tener un buen o mal sentido de la estética no significa mucho si nuestros datos no son claros. Por lo tanto, es necesario comprender lo que queremos expresar, lo cual puede ser una tarea difícil si no reflexionamos sobre por qué estamos haciendo este tipo de representación. A veces, podemos utilizar tablas para resumir cantidades y/o patrones, pero la gran gestión de datos de hoy en día hace que esto sea una tarea compleja e ineficiente. Por lo tanto, volvamos a la pregunta principal: ¿por qué visualizar? ¿Por qué no hacer simplemente tablas que expresen lo que queremos decir? A través de la visualización de datos podemos entender otros tipos de problemas que los números por sí solos no pueden mostrar. Mediante la visualización, queremos explorar y comprender nuestros datos. Además, la representación gráfica puede ayudarnos a interpretar patrones, tendencias, distribuciones y a comunicarlos mejor a nuestros lectores.
Figura 3.1: Estadística Florence Nightingale (1820-1910).
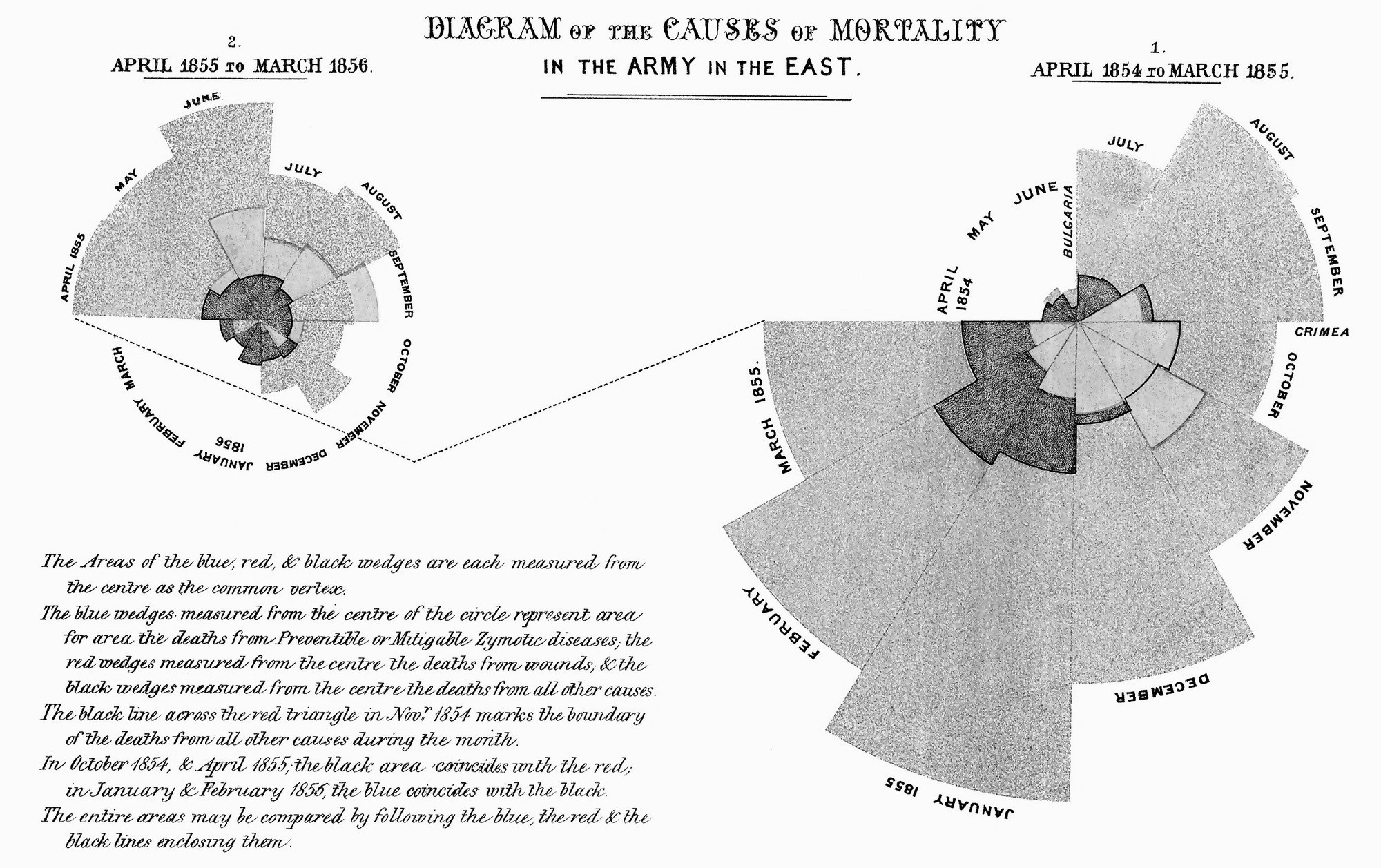
Figura 3.2: Diagrama de las causas de muerte en el ejército británico
En rojo se destacan las muertes por heridas de guerra, en azul las muertes debidas a enfermedades evitables, y en negro, las muertes causadas por otro tipo de causas. Este gráfico no sólo proporciona información cuantitativa sobre las muertes, sino que también señala un problema sustancial en el sistema de salud de los militares en ese momento.
El diagrama de Nightingale reveló el problema, que fue el paso inicial para una serie de reformas. Así, la visualización se convierte en una herramienta que puede ser aplicada en todas las etapas de la investigación. En una etapa inicial, es importante para la exploración de los datos, y para entender cómo se relacionan las variables entre sí, sus distribuciones y frecuencias. Al interpretar los datos, la visualización es útil para mostrar posibles tendencias o patrones en los datos. Por último, la visualización es una gran herramienta para la difusión del conocimiento. Pero recuerde, con un gran poder viene una gran responsabilidad, y las relaciones espurias dejan de ser graciosas cuando la gente se las toma demasiado en serio12. Monogan (2015cap. 3) ya había explicado de forma sencilla para los científicos sociales, por qué la visualización de datos es importante cuando se trabaja con datos cuantitativos. En la introducción del capítulo, Monogan afirma la importancia y las ventajas de trabajar con cifras, desde la simple distribución de variables, valores atípicos o sesgos, hasta las tendencias a lo largo del tiempo. Por esta razón, la visualización de datos es una herramienta crucial para cualquiera que trabaje con datos. No es, de ninguna manera, un “movimiento estético,” la gráfica es extremadamente útil.
Sin embargo, para algunas personas, la visualización de datos es tanto un elemento funcional para el análisis como un elemento estético por excelencia. Para Edward Tufte (2006), visualizar los datos de manera efectiva tiene un componente artístico inevitable. Con formación de estadístico y un doctorado en Ciencias Políticas de la Universidad de Yale, Edward Tufte se dedicó a entender y explicar cómo la ciencia y el arte tienen en común una observación a ojos abierto que genera información empírica. Su libro Beautiful Evidence (Tufte 2006) describe el proceso de cómo observar se transforma en mostrar, y cómo la observación empírica se convierte en explicaciones y pruebas.
Necesitamos entender que la visualización de datos es un lenguaje como cualquier otro. Como emisores, necesitamos conocer nuestra audiencia: quiénes son los receptores de nuestro mensaje, si es una audiencia experta o sólo el público en general. En cualquier circunstancia, ajustaríamos nuestro mensaje al tipo de audiencia. Lo mismo ocurre cuando visualizamos los datos. Los gráficos que hacemos deben adaptarse a nuestro público. Sin embargo, incluso con las personas más conocedoras no debemos entusiasmarnos demasiado. No se trata de aplicar todo lo que sabemos inmediatamente, sino de entender lo que estamos tratando de comunicar. Comprender las funciones de este lenguaje es esencial.
En la siguiente subsección hablaremos de cómo funciona ggplot2. A partir de ahora, comenzaremos con ejemplos aplicados. Los tipos de representación visual más comunes son el histograma, el gráfico de barras, el gráfico de densidad y el gráfico de líneas. Además, introduciremos otros paquetes de utilidades para hacer gráficos más sofisticados. Finalmente, aprenderemos sobre otros paquetes que pueden ser útiles dentro de las ciencias sociales, y en particular, las ciencias políticas, como son sf y ggparliament.
Consejo: Después de este capítulo, si quieres aprender más sobre la visualización de datos, consulta Data Visualization: A Practical introduction de Kieran Healy, un libro disponible de forma gratuita que es divertido y útil para aprender
ggplot2paso a paso. En este libro no sólo encontrará una parte teórica, sino también una práctica. Por otro lado, la página web From Data to Viz puede ayudarte a aprender a presentar tus datos, pero no sólo eso: tanto si trabajas con R como con Python, puedes encontrar los paquetes y códigos para su aplicación.
3.2 Primeros pasos
Ahora que entendemos el proceso antes de construir un gráfico, tenemos que familiarizarnos con ggplot2, el paquete para crear gráficos que es parte del tidyverse. A Layered Grammar of Graphics, de Hadley Wickham, explica en detalle cómo funciona esta nueva “gramática” para hacer gráficos. Recomendamos que se lea de la fuente original cómo se creó este paquete para entender más tarde el uso de las capas en la construcción de los gráficos.
Aunque el uso de ggplot2 se expandió rápidamente, dentro de la comunidad R hay constantes discusiones sobre la enseñanza de ggplot2 como primera opción sobre los gráficos base de R. Por ejemplo, David Robinson tiene en su blog diferentes entradas sobre este tema, donde explica en detalle las ventajas de ggplot2 sobre otras opciones. Si eres un principiante en R, empezar con ggplot2 te dará una herramienta poderosa, y su curva de aprendizaje no es tan empinada como las R básico.
Algunas ventajas que David Robinson menciona en “Por qué uso ggplot2”13 son:
- Subtítulos. R básico requiere más conocimiento de los usuarios para poder añadir subtítulos en los gráficos. Nuestro amigo
ggplot2lo hace automáticamente. - ¡Facetas! Básicamente, podemos crear subgráficos con una tercera o cuarta variable y superponerlos, lo que nos permitirá una mejor comprensión del comportamiento de nuestros datos.
- Funciona junto con
tidyverse. Esto significa que podemos hacer más con menos. Al final de este capítulo entenderán lo que quiero decir. Hay atajos para todo. - Estéticamente, es mejor. Hay miles de opciones de paletas cromáticas, temas y fuentes. Si no te gusta, hay una forma de cambiarlo.
Con esto en consideración, empecemos con lo práctico.
3.2.1 Las capas del “universo ggplotiano”
Empecemos con nuestro tema de interés: ¿Cómo funciona ggplot2? Este paquete está incluido en el tidyverse, por lo que no es necesario cargarlo por separado. Además, utilizaremos las herramientas de ambos paquetes a lo largo de todo el capítulo. Así, el primer paso es cargar el paquete:
library(tidyverse)La intuición detrás de ggplot2 es directa. La construcción de los datos se basa en capas que contienen un cierto tipo de información.
3.2.1.1 Datos
La primera capa corresponde a los datos que usaremos. Para hacerlo más demostrativo, cargaremos la base datos que se utilizarán a lo largo del capítulo.
library(paqueteadp)
data("datos_municipales")El conjunto de datos debería estar ahora en nuestro ambiente. Estos datos corresponden a la información de los municipios chilenos. Algunos son del Servicio Electoral y otros del Sistema Nacional de Información Municipal de Chile. En la primera base de datos, encontramos los resultados electorales de las elecciones locales, regionales y nacionales del país; mientras que en la segunda encontramos las características económicas, sociales y demográficas de los municipios chilenos. En este caso, tenemos los datos electorales comunales de 1992 a 2012, con datos descriptivos como la población, el ingreso total del municipio, el gasto en asistencia social y el porcentaje de personas en situación de pobreza en base al total comunal de la Encuesta de Caracterización Socioeconómica Nacional (CASEN).
glimpse(datos_municipales)
## Rows: 1,011
## Columns: 6
## $ anio <chr> "2004", "2004", "2004", "2004", "2004", "2004", "~
## $ zona <chr> "Norte Grande", "Norte Grande", "Norte Grande", "~
## $ municipalidad <chr> "Alto Hospicio", "Arica", "Camarones", "Camina", ~
## $ genero <chr> "0", "0", "1", "0", "0", "0", "0", "0", "0", "0",~
## $ ingreso <int> 1908611, 12041351, 723407, 981023, 768355, 558068~
## $ pobreza <dbl> NA, 23.5, 10.6, 37.3, 58.3, 38.8, 31.3, 7.6, 23.6~Al mirar a la base de datos, encontramos que hay variables continuas (numéricas) y categóricas (de texto). Saber con qué tipo de variable estamos trabajando es esencial para el siguiente paso.
3.2.1.2 Mapeos estéticos
La segunda capa corresponde al mapeo de las variables dentro del espacio. En este paso, usamos mapping=aes(), que contendrá la variable que tendremos en nuestros ejes x e y. Para aes(), hay muchas opciones que veremos a lo largo del capítulo: algunas de ellas son, por ejemplo, fill, color, shape, y alpha. Todas estas opciones son un conjunto de señales que nos permitirán traducir mejor lo que queremos decir a través de nuestro gráfico. Normalmente, estas opciones se llaman estéticas o aes().
ggplot(data = datos_municipales,
mapping = aes(x = anio, y = pobreza))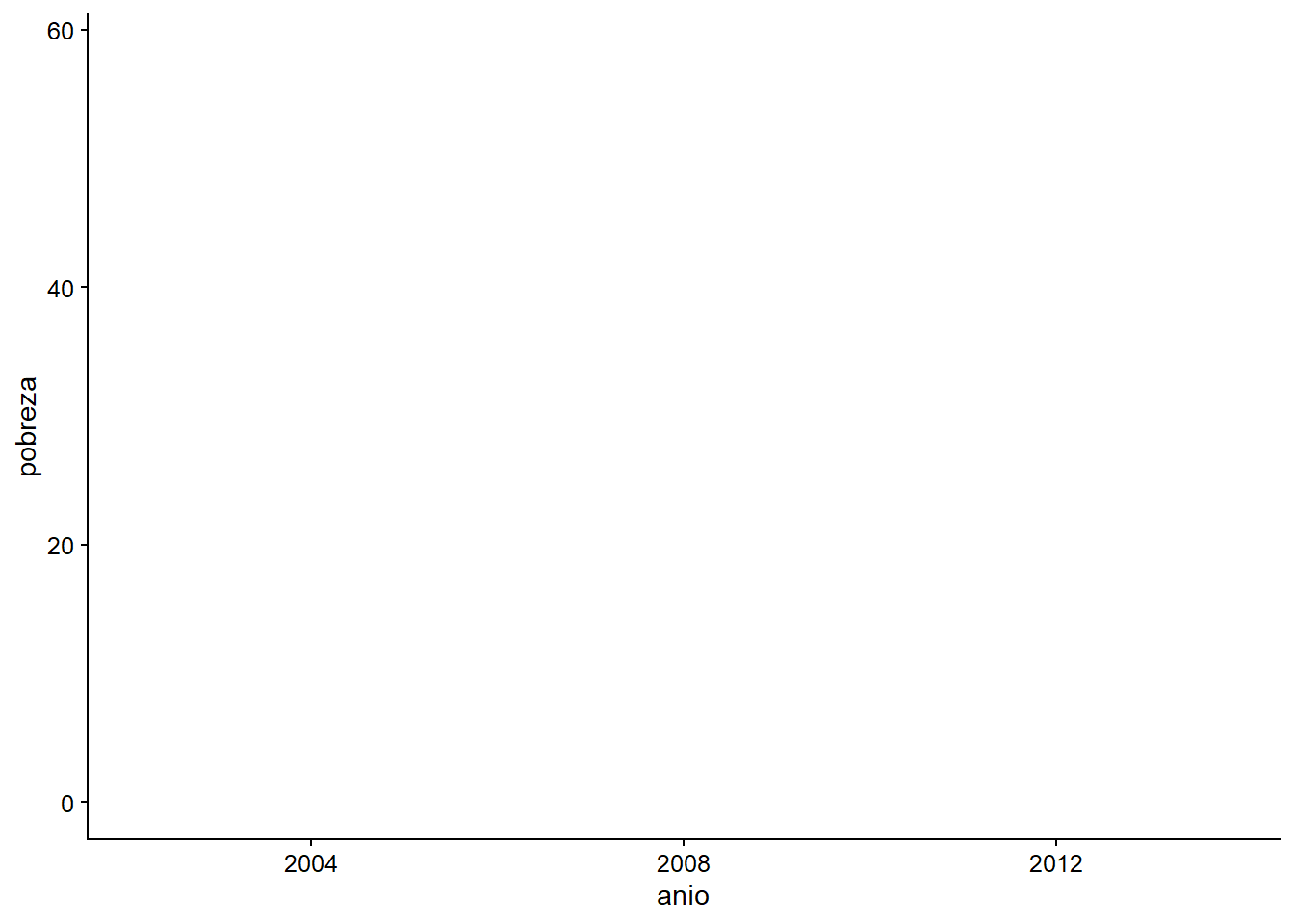
Figura 3.3: Marco vacío.
El resultado muestra un marco vacío. Esto se debe a que no le hemos dicho a R qué objeto geométrico usar.
3.2.1.3 Objeto geométrico
Suena extraño, pero cuando hablamos del objeto geométrico o geom, nos referimos al tipo de gráfico que queremos hacer, ya sea un gráfico lineal, un gráfico de barras, un histograma, un gráfico de densidad, o un gráfico de puntos, o si queremos hacer un gráfico de cajas. Esto corresponde a la tercera capa. En este caso, ya que tenemos datos de la encuesta CASEN, haremos un gráfico de caja para ver cómo se distribuyen los municipios en nuestra muestra.
ggplot(data = datos_municipales,
mapping = aes(x = anio, y = pobreza)) +
geom_boxplot()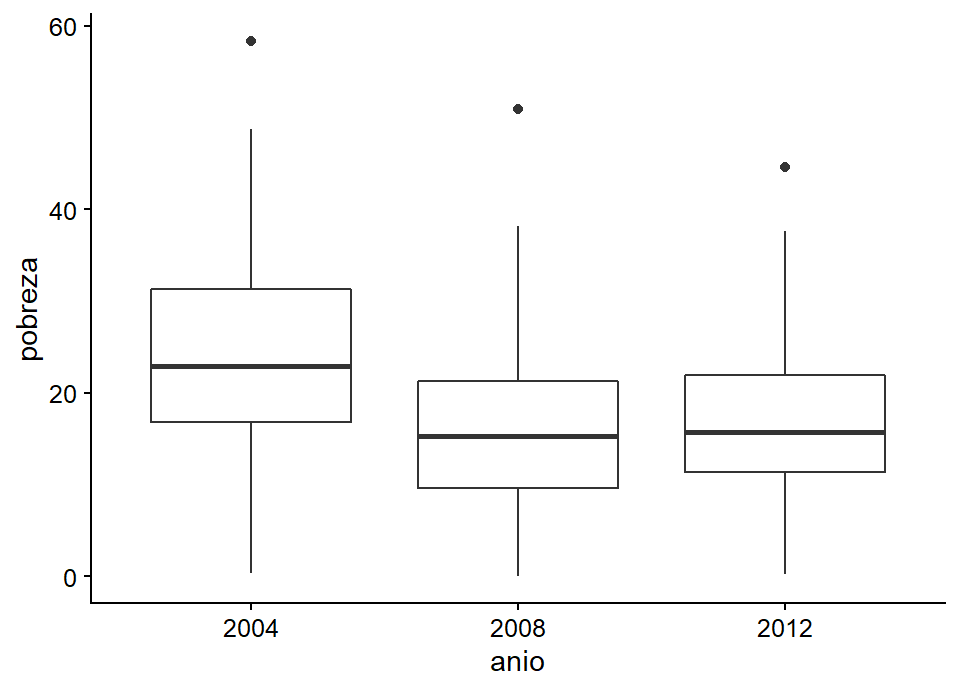
Figura 3.4: Añadiendo un objeto geométrico a su gráfica.
Lo primero que notamos es la ausencia de datos durante tres períodos. Desafortunadamente, no hay datos anteriores a 2002, por lo que no se encuentran entradas para esos años. Por ello, es una gran idea filtrar los datos y dejar sólo los años que contienen datos sobre la encuesta CASEN. Además de eso, nuestro gráfico no nos dice mucho sobre el porcentaje de pobreza y su distribución. Considerando la geografía de Chile, es una gran idea ver la distribución de la pobreza por zona de la región geográfica.
3.2.1.4 Facetas
Ahora, usaremos nuestras nuevas habilidades para hacer dos cosas: primero, usaremos filter() para conservar sólo los años que nos interesan. Segundo, dividiremos los resultados por zonas usando facet_wrap(), que corresponde a la cuarta capa que podemos usar para construir un gráfico con ggplot2. Cuando usamos esta capa, lo que queremos es organizar las “geoms” que estamos usando en función de una variable categórica. En este caso, la zona. Sin embargo, las facetas, como acción, son mucho más que eso. facet_wrap() y facet_grid() pueden adoptar una serie de argumentos, siendo el primero el más importante. En este caso, la sintaxis que utilizamos es la misma que se usa para las fórmulas en R, y denotamos el primer argumento con un signo “~.” Con los argumentos nrow = y ncol = podemos especificar cómo queremos ordenar nuestro gráfico.
Finalmente, añadimos dos líneas de código, una para filtrar y otra para subdividir nuestra información. Esto es lo que logramos:
ggplot(data = datos_municipales %>% filter(anio == c(2004, 2008, 2012)),
mapping = aes(x = anio, y = pobreza)) +
geom_boxplot() +
facet_wrap(~ zona, nrow = 1)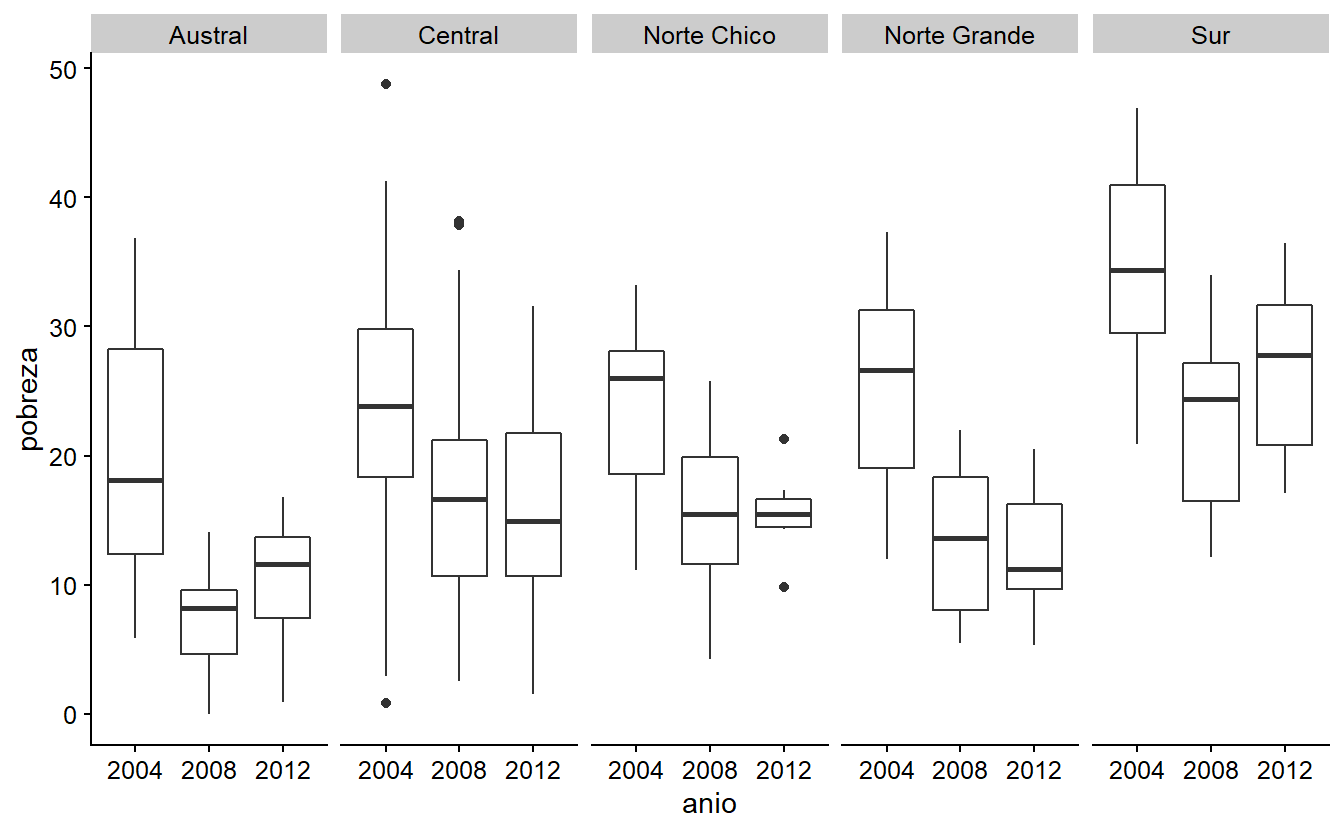
Figura 3.5: Añadiendo una faceta a su gráfico.
Tanto con facet_wrap() como con facet_grid() podemos usar más de un argumento, pero los resultados son diferentes. facet_wrap() no sólo ordena los geoms, sino que es capaz de cruzarlos, creando gráficos con dos o más dimensiones usando variables categóricas. Mira los siguientes ejemplos:
ggplot(data = datos_municipales%>% filter(anio == c(2004, 2008, 2012)),
mapping = aes(x = anio, y = pobreza)) +
geom_boxplot() +
facet_wrap(zona ~ genero)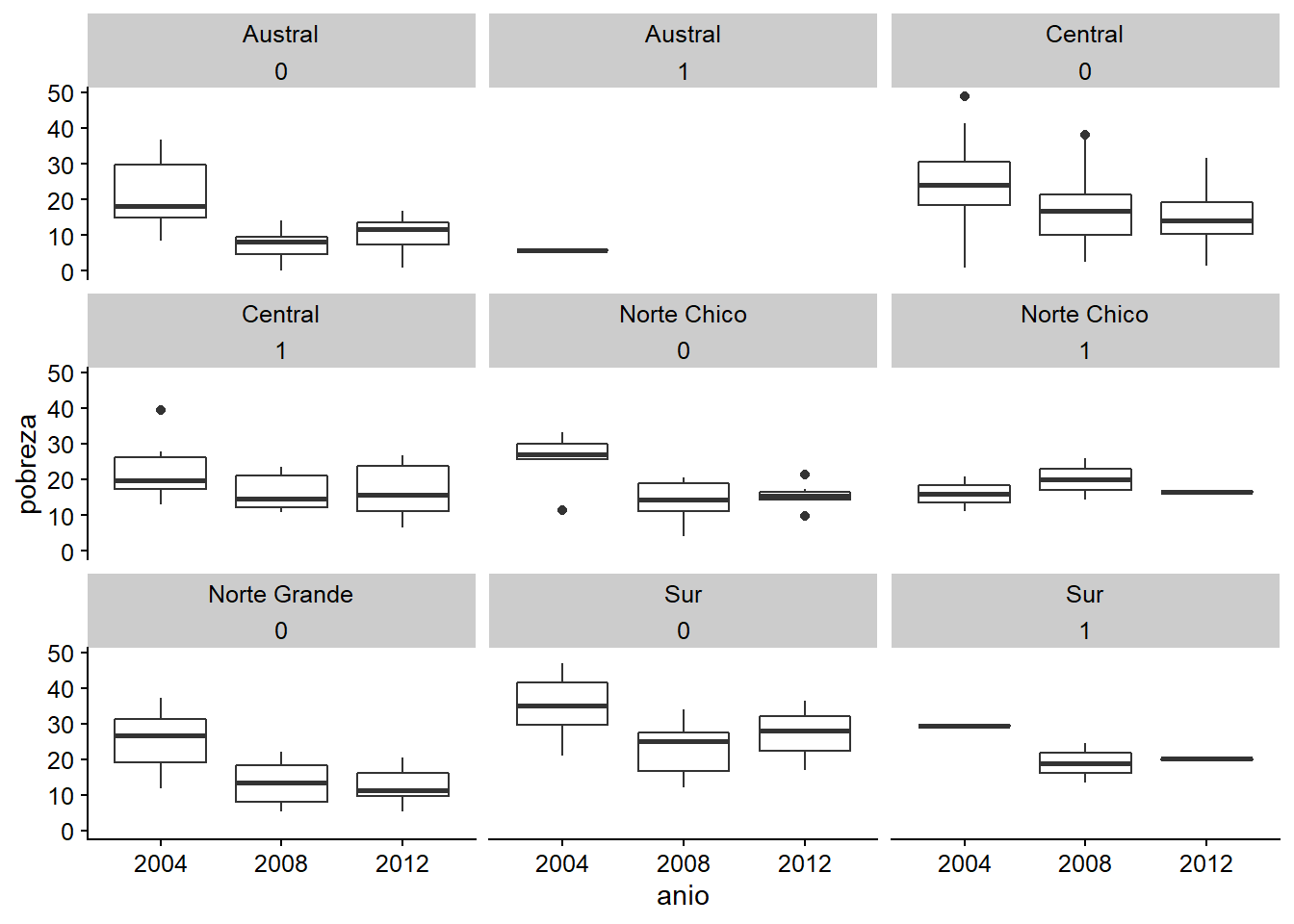
Figura 3.6: Comparando wraps y grillas, ejemplo A.
ggplot(data = datos_municipales %>% filter(anio == c(2004, 2008, 2012)),
mapping = aes(x = anio, y = pobreza)) +
geom_boxplot() +
facet_grid(zona ~ genero)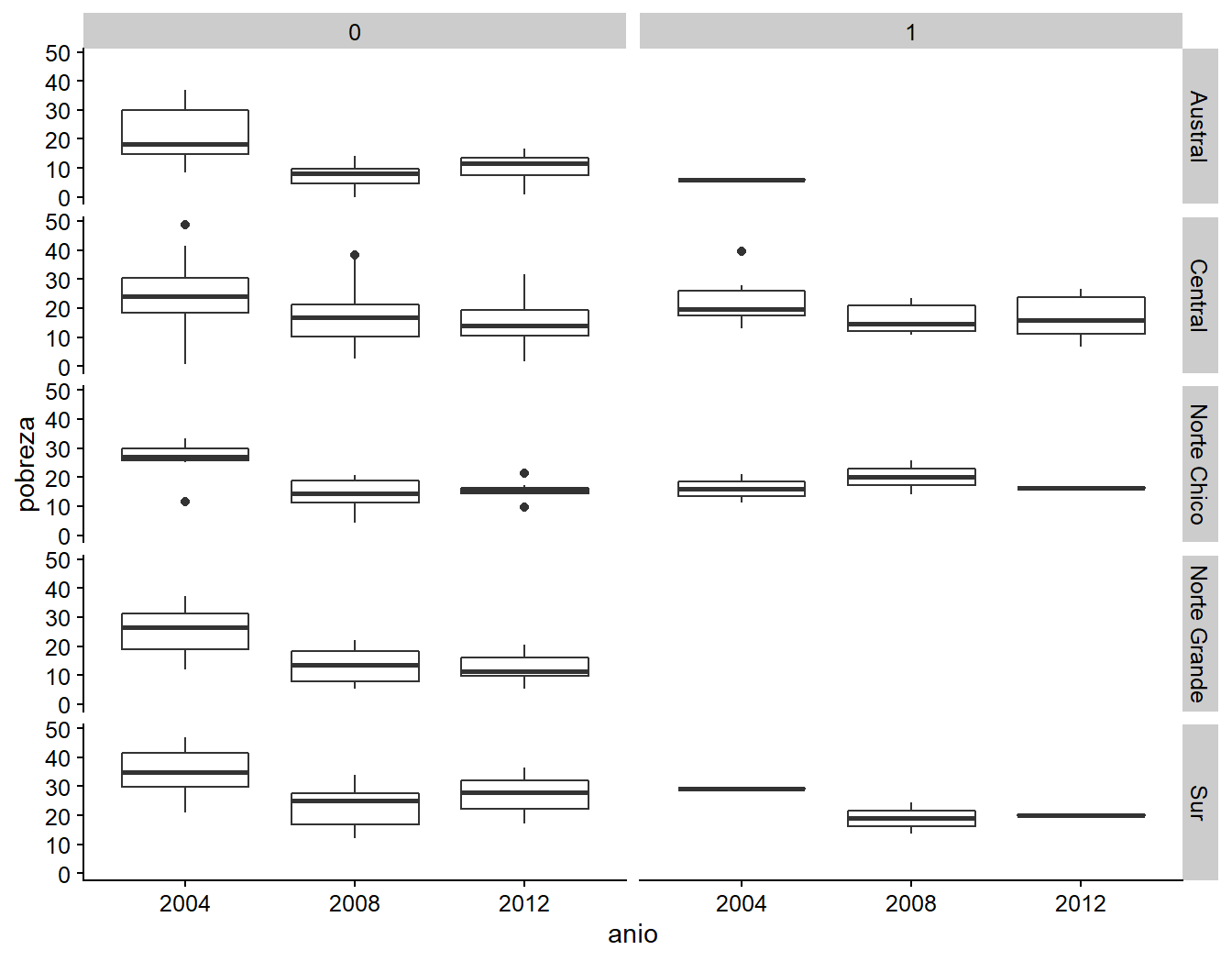
Figura 3.7: Comparando wraps y grillas, ejemplo B.
Este gráfico muestra que, por zonas, el porcentaje de pobreza ha variado considerablemente de 2004 a 2012, y que existe una gran variabilidad interregional. Además, nos muestra cómo ggplot2 ofrece resultados de alta calidad sin mucha complejidad. La función facet_wrap() es una capa opcional dentro de las múltiples capas de “Una Gramática de Gráficos en Capas,” pero es importante recordar que las otras tres deben estar presentes para cualquier tipo de resultados.
3.2.1.5 Transformaciones
Otra capa que se puede usar es la que nos permite hacer transformaciones de escala en las variables. Normalmente, aparecerá con el nombre scale_x_discrete(), que variará dependiendo de la estética utilizada dentro de nuestro mapeo. Así, podemos encontrarnos con scale_fill_continous() o scale_y_log10(). Por ejemplo, podemos ver cómo se distribuyen los ingresos de los municipios según la tasa de pobreza de nuestra muestra. Normalmente, haríamos esto de la siguiente manera:
ggplot(data = datos_municipales %>% filter(anio == c(2004, 2008, 2012)),
mapping = aes(x = pobreza, y = ingreso)) +
geom_point()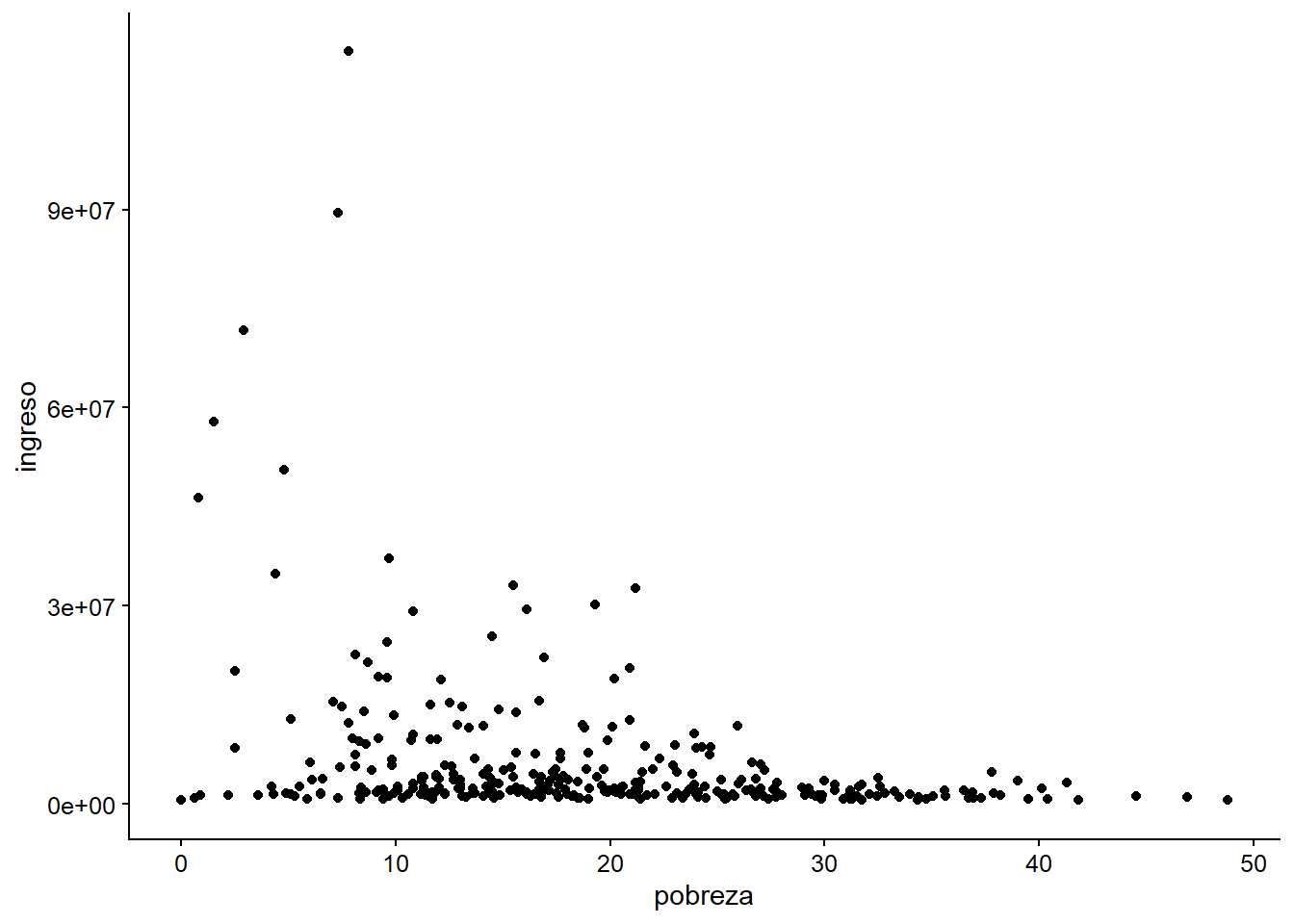
Figura 3.8: Ejemplo de una gráfica en la que no utilizamos la escala.
Lo más frecuente es que cuando usamos una variable relacionada con el dinero, aplicamos una transformación logarítmica. Sin embargo, ¿cómo se traduce esto en nuestra figura?
ggplot(data = datos_municipales %>% filter(anio == c(2004, 2008, 2012)),
mapping = aes(x = pobreza, y = ingreso)) +
geom_point() +
scale_y_log10()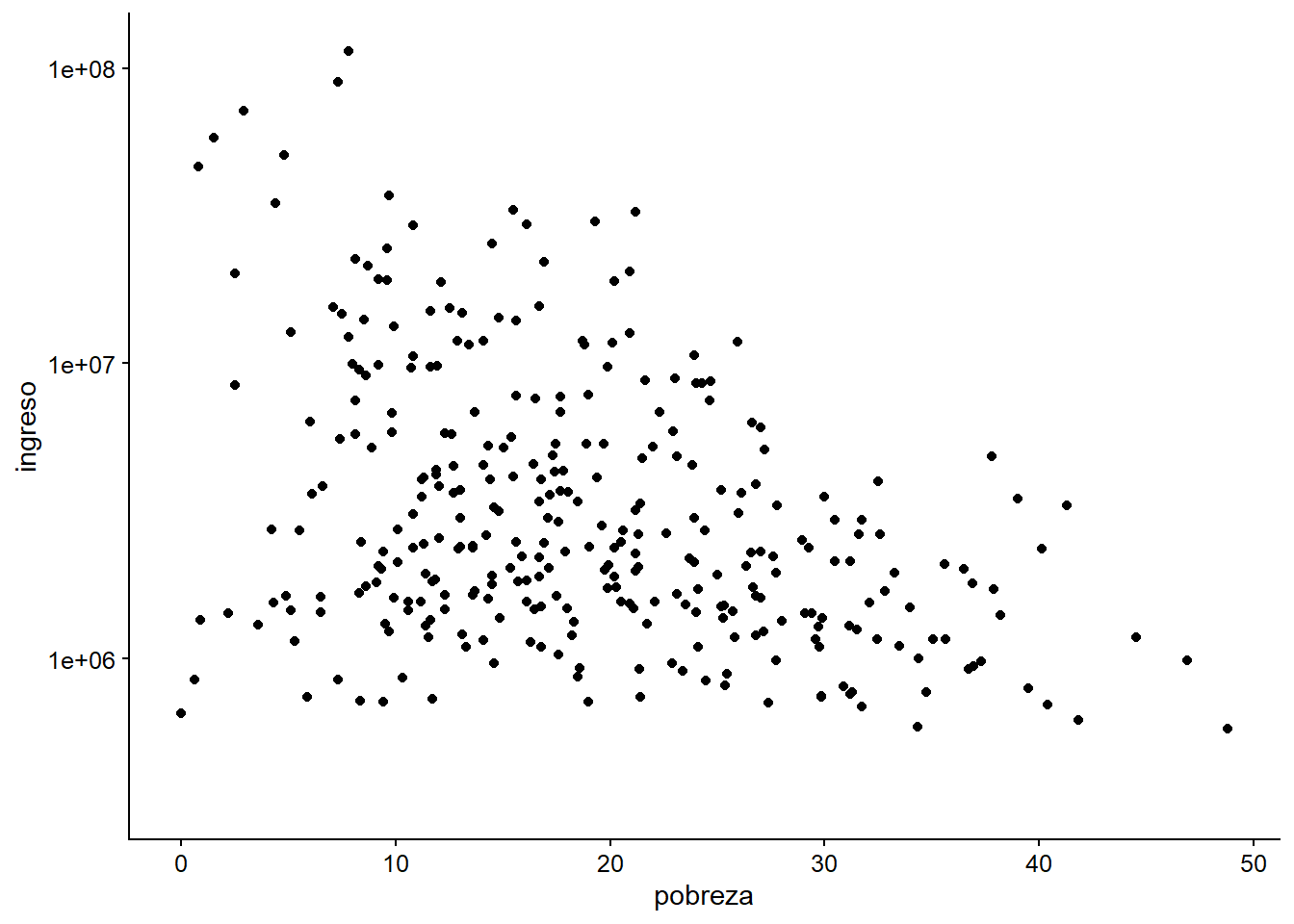
Figura 3.9: Ejemplo de una trama en la que reescalamos el eje y.
3.2.1.6 Sistema de coordenadas
Por lo general, trabajaremos con un eje X y un eje Y. Hay funciones en ggplot2, como coord_flip, que nos permiten cambiar la dirección de nuestra gráfica. Sin embargo, también podemos utilizar este tipo de capa cuando trabajamos con datos geográficos, o cuando, por ejemplo, queremos hacer un gráfico de torta. Sin embargo, normalmente, no queremos hacer gráficos de pastel. Cuanto más se utilice ggplot2, más se aprenderá sobre cada opción.
3.2.1.7 Temas
Cuando hacemos un mapeo de datos, usamos opciones estéticas. Cuando queremos cambiar el aspecto de un gráfico, cambiamos el tema. Esto se puede hacer a través de theme(), que permite modificar cosas que no están relacionadas con el contenido del gráfico. Por ejemplo, los colores de fondo o la fuente de las letras en los ejes. También puedes cambiar el lugar donde se ubicará la leyenda o el título. Por último, también puedes cambiar el título, el nombre de los ejes, añadir anotaciones, etcétera. Sólo tienes que saber labs() y annotate().
Ahora es el momento de aplicar todo lo que “aparentemente” ya entendemos.
3.3 Ejemplo aplicado: Elecciones locales y visualización de datos
Como hemos mencionado anteriormente, la cuestión principal es entender que la visualización nos permite explorar nuestros datos y responder a preguntas sustantivas de nuestra investigación. Normalmente, los medios, las desviaciones estándar u otro tipo de parámetros no nos dicen mucho. Podemos expresar los mismos datos visualizándolos. Por ejemplo, un diagrama de caja puede ser útil para representar la distribución de los datos y ver sus posibles valores atípicos, mientras que un gráfico de barras puede ayudarnos a observar la frecuencia de nuestros datos categóricos, y un gráfico lineal es práctico para comprender el cambio a lo largo del tiempo. Estos son sólo algunos ejemplos dentro de una variedad de posibilidades. En esta tercera sección, aprenderemos a visualizar diferentes tipos de gráficos con datos de la reelección municipal en Chile. Para contextualizar, la división político-administrativa más pequeña de Chile es la comuna o municipio, que cada cuatro años elige a sus autoridades locales: un alcalde y un consejo municipal. Desde 1992 a 2000, los alcaldes fueron elegidos indirectamente, y desde 2004 comenzaron a ser elegidos directamente por los ciudadanos.
Como ya conocemos nuestros datos, podemos empezar con los más simples. Una buena idea, por ejemplo, es ver el número de mujeres elegidas como alcaldes en comparación con el número de hombres elegidos. Para ello, podemos utilizar un gráfico de barras. Como aprendimos en la sección anterior, para construir cualquier tipo de gráfico necesitamos saber la(s) variable(s) que queremos usar y qué geometría o geom nos permite representarla. En este caso, usaremos geom_bar() para ver cuántos hombres y mujeres han sido elegidos desde 1992.
3.3.1 Gráfico de barras
plot_a <- ggplot(datos_municipales, mapping = aes(x = genero))
plot_a +
geom_bar()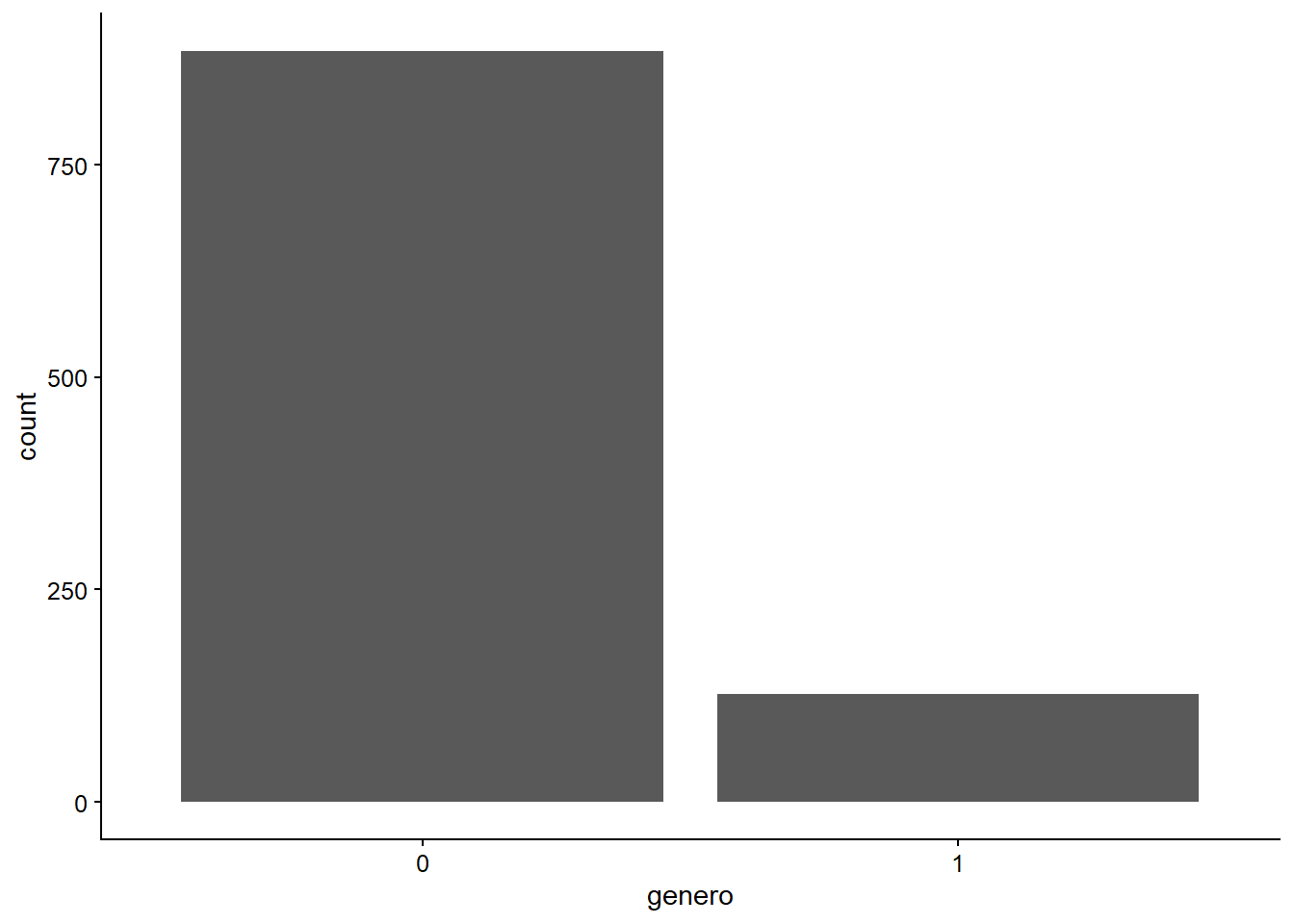
Figura 3.10: Gráfica simple de barras.
Como podemos ver, construir un gráfico de barras es una tarea fácil. Vemos que, a partir de 2004, más de 800 hombres fueron elegidos como alcaldes, un número que supera con creces el número de mujeres elegidas para el mismo cargo en el mismo período.
Tal vez, este número ha cambiado con el tiempo, y no podemos verlo en este tipo de gráfico? Esto parece ser una buena razón para usar facet_wrap.
plot_a +
geom_bar() +
facet_wrap(~anio, nrow = 1)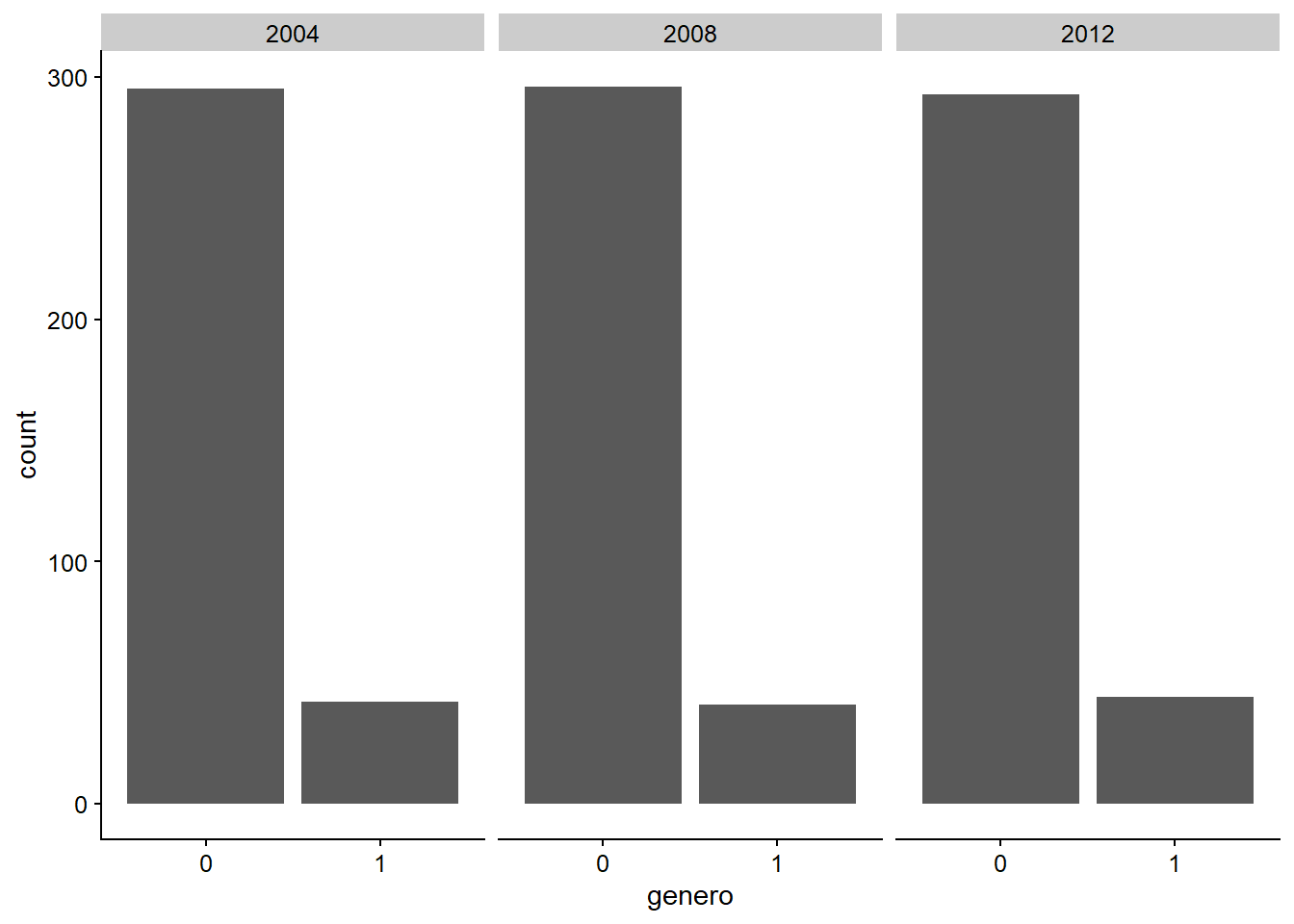
Figura 3.11: Gráfico de barras con una faceta por año.
Como vemos, el número de mujeres alcaldesas parece aumentar, aunque es un aumento mucho menor del que se esperaría. Esto podría ser un problema sustantivo para hacer un análisis del gobierno local en Chile.
Geometrías como geom_bar, geom_col, geom_density y geom_histogram tienden a no llevar un eje Y explícito en su estética, ya que son un recuento en el eje horizontal. Sin embargo, uno puede modificar el eje vertical en estas geometrías aplicando algún tipo de transformación. Por ejemplo, al especificar y=..prop.. como una estética dentro del objeto geométrico, estamos ordenando el cálculo de la proporción, no el conteo. Normalmente, usaremos aes() además de los datos en ggplot(), pero dependiendo de tus
preferencias, también es posible usarlo con geom. Esta última es más común cuando ocupamos más de una base de datos o cuando queremos hacer una transformación.
Por ejemplo, podríamos estar interesados en el número de autoridades locales por zona geográfica. Para ello, sería útil utilizar una proporción, ya que cada zona geográfica está formada por un número diferente de municipios. De esta manera, será más fácil comparar la situación entre las zonas.
plot_a +
geom_bar(mapping = aes(y = ..prop.., group = 1)) +
facet_wrap(~zona, nrow = 1)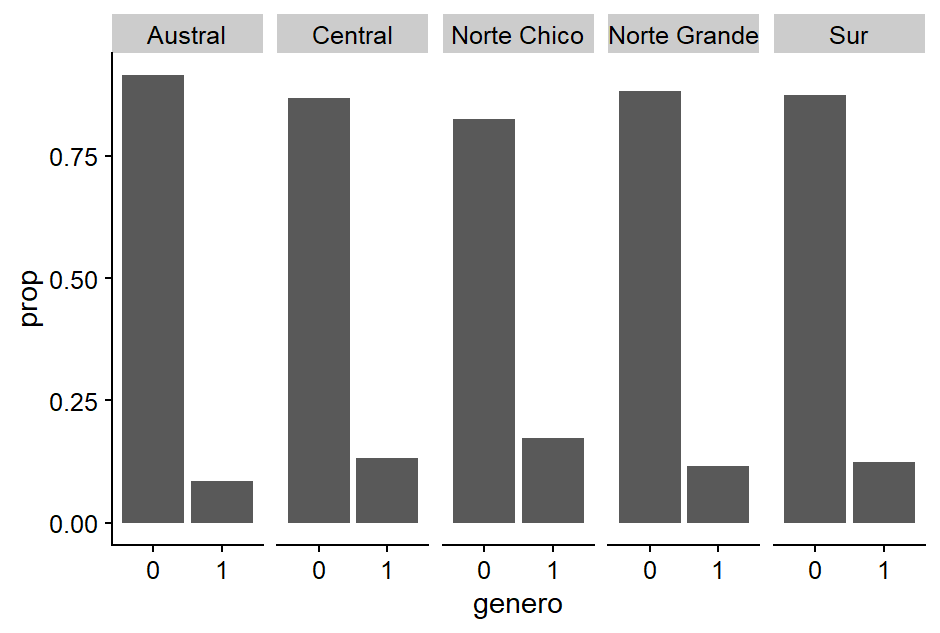
Figura 3.12: Gráfico de barras con una faceta por zona.
¿Pero por qué usamos grupo=1?
Cuando queremos calcular una proporción con y=..prop.., tenemos que tomar algunas precauciones si estamos usando facet_wrap. Esta función no calcula la proporción basada en la suma de ambos géneros por zona. Por ejemplo, esta función registra que hay 89 hombres y 13 mujeres elegidos en la zona del Gran Norte. Concluye que “en el Gran Norte, los 89 hombres corresponden al 100% de los hombres elegidos y las 13 mujeres al 100% de las mujeres elegidas.” Claramente, esto no es lo que intentamos representar en el gráfico. Por eso usamos group=1. Intenta ver el resultado sin group=1 para comprobar lo que sucede.
Ya lo hemos hecho! Vemos que no hay grandes diferencias, donde la zona del “Norte Pequeño” es la que tiene más mujeres en la alcaldía que hombres. Sin embargo, no hay grandes diferencias entre las zonas, y los resultados del primer gráfico de barras se replican en este.
Ahora, podemos cambiar la presentación del gráfico. Todo buen gráfico debe contener, por ejemplo, un título claro, la fuente de los datos y el detalle de los ejes.
Sugerencia. El Chicago Guide to Writing about Multivariate Analysis (Miller 2013) tiene muchos buenos consejos sobre cómo crear gráficos efectivos.
plot_a +
geom_bar(mapping = aes(y = ..prop.., group = 1)) +
facet_wrap(~zona, nrow = 1) +
labs(title = " Proporción de hombres y mujeres elegidos como alcaldes
(2004-2012)\n Por zonas económicas de Chile",
x = "Género", y = "Proporción",
caption = " Fuente: Basado en datos de SERVEL y SINIM (2018)") 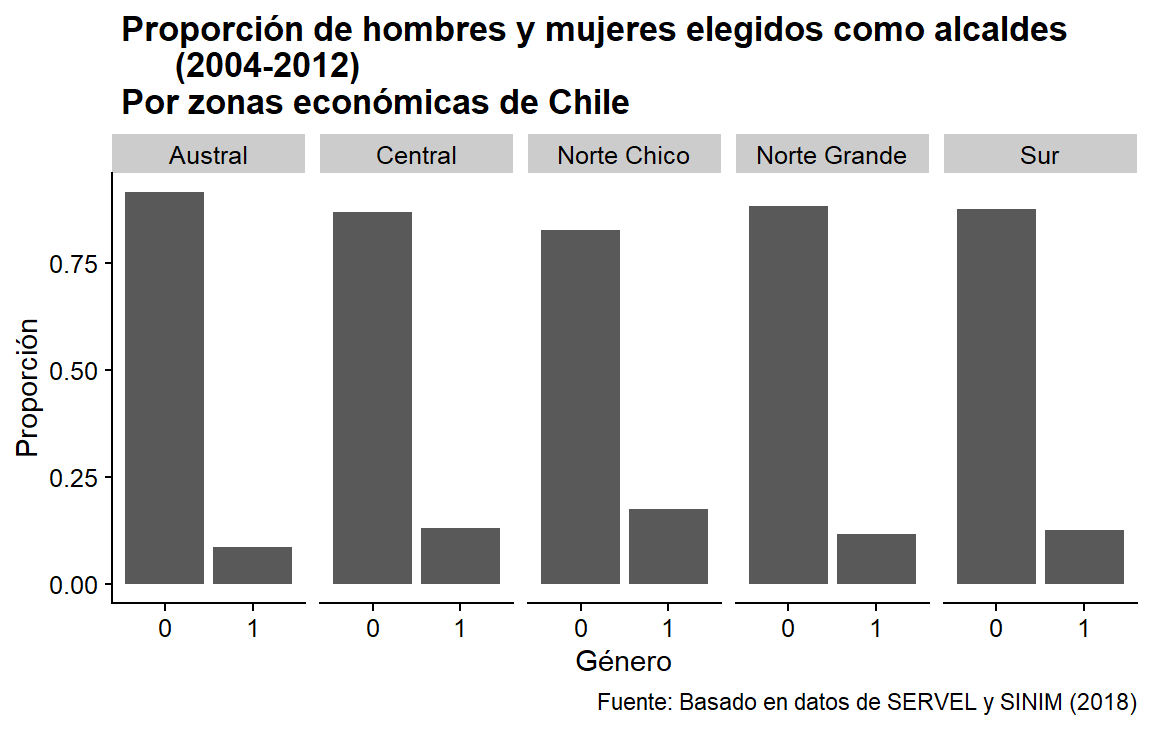
Figura 3.13: Gráfico de barras con título y fuentes.
Ahora, sólo tenemos que añadir etiquetas para el eje X. Podemos hacerlo fácilmente con scale_x_discrete(). Tienes que considerar qué estética de aes() modificarás, ya que esto cambiará la scale = que necesitas. Si examináramos las etiquetas desde fill =, por ejemplo, tendríamos que usar scale_fill_discrete(). También hay que tener en cuenta el tipo de variable que se utiliza. scale_x_discrete() no tiene “discrete” al final sin motivo. Como comprenderás, depende totalmente del tipo de variable que estamos usando.
plot_a +
geom_bar(mapping = aes(y = ..prop.., group = 1)) +
facet_wrap(~zona, nrow = 1) +
scale_x_discrete(labels = c("Hombres", "Mujeres")) +
labs(title = " Proporción de hombres y mujeres elegidos como alcaldes
(2004-2012)\n Por zonas económicas de Chile ",
x = "Género", y = "Proporción",
caption = " Fuente: Basado en datos de SERVEL y SINIM (2018)") 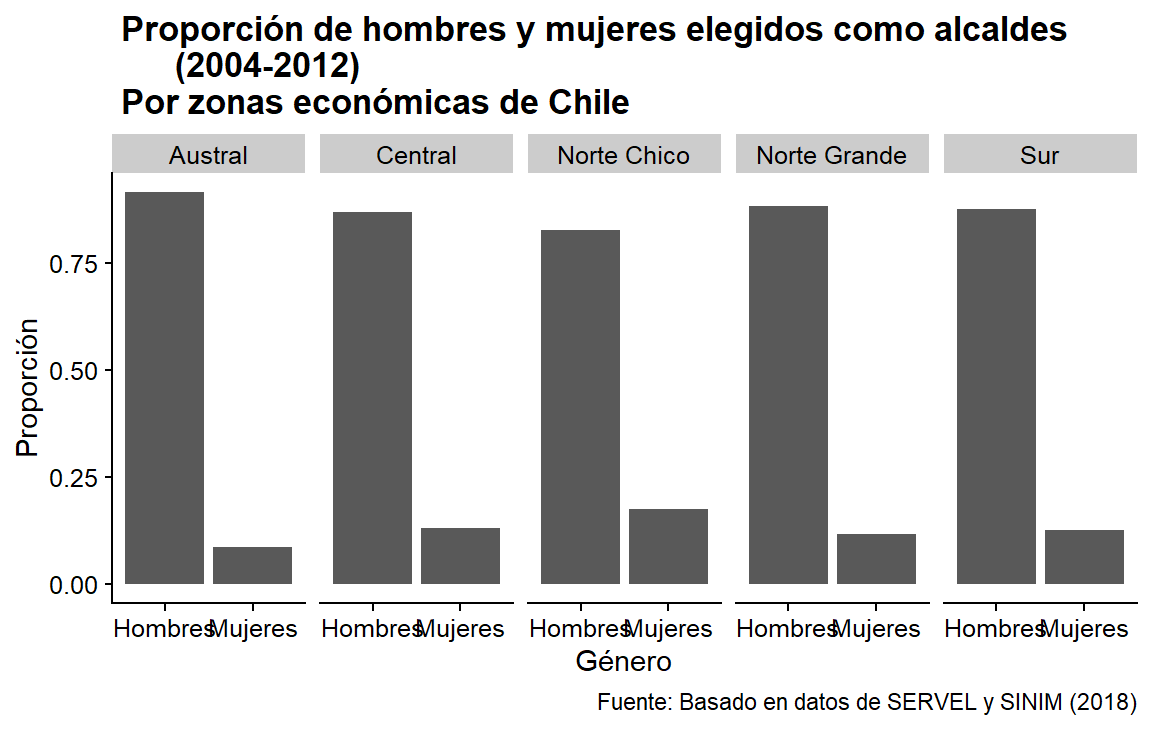
Figura 3.14: Gráfica con etiquetas de grupo
Consejo. Con
labels =podemos cambiar las etiquetas. Considera el número de valores de tu variable categórica para que coincidan con la variable, y no pierdas ninguna categoría.
3.3.2 Gráfico de líneas
En el último gráfico de la sección anterior vimos que, aunque la elección de mujeres como alcaldesas en Chile ha aumentado, este aumento no parece ser significativo: en 2012, sólo el 13% de los alcaldes elegidos eran mujeres. Tal vez esto se deba a que los cambios socioeconómicos no han afectado las percepciones de los roles de género en la sociedad. El examen de los datos económicos de los ingresos municipales o del porcentaje de pobreza según la CASEN podría ayudarnos a comprender por qué la elección de mujeres en las instancias municipales no ha aumentado sustancialmente. Para ello, podemos utilizar geom_line, el objeto geométrico que permite observar la evolución en el tiempo de nuestro sujeto de interés. La intuición sería hacer la figura de esta manera:
plot_b <- ggplot(data = datos_municipales,
mapping = aes(x = anio, y = ingreso))
plot_b +
geom_line()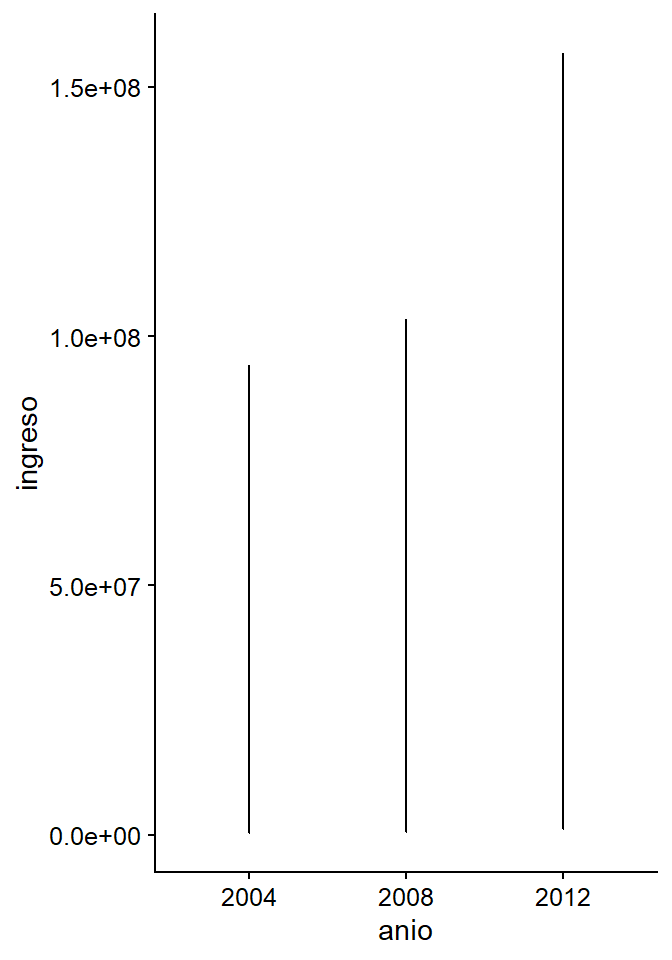
Figura 3.15: Una especificación errónea para un gráfico de líneas.
El problema es que no da el resultado esperado. La intuición es correcta, pero tenemos que ayudar a geom_line() con algunas especificaciones. En este caso, se agrupa por lo que tiene más sentido: por año. Por eso tenemos que especificar cuál es la variable que agrupa toda la información y, como sabemos, la información que poseemos está agrupada por municipio. Cuando añadimos esta información, el resultado cambia y se parece a lo que buscamos:
plot_b +
geom_line(mapping = aes(group = municipalidad))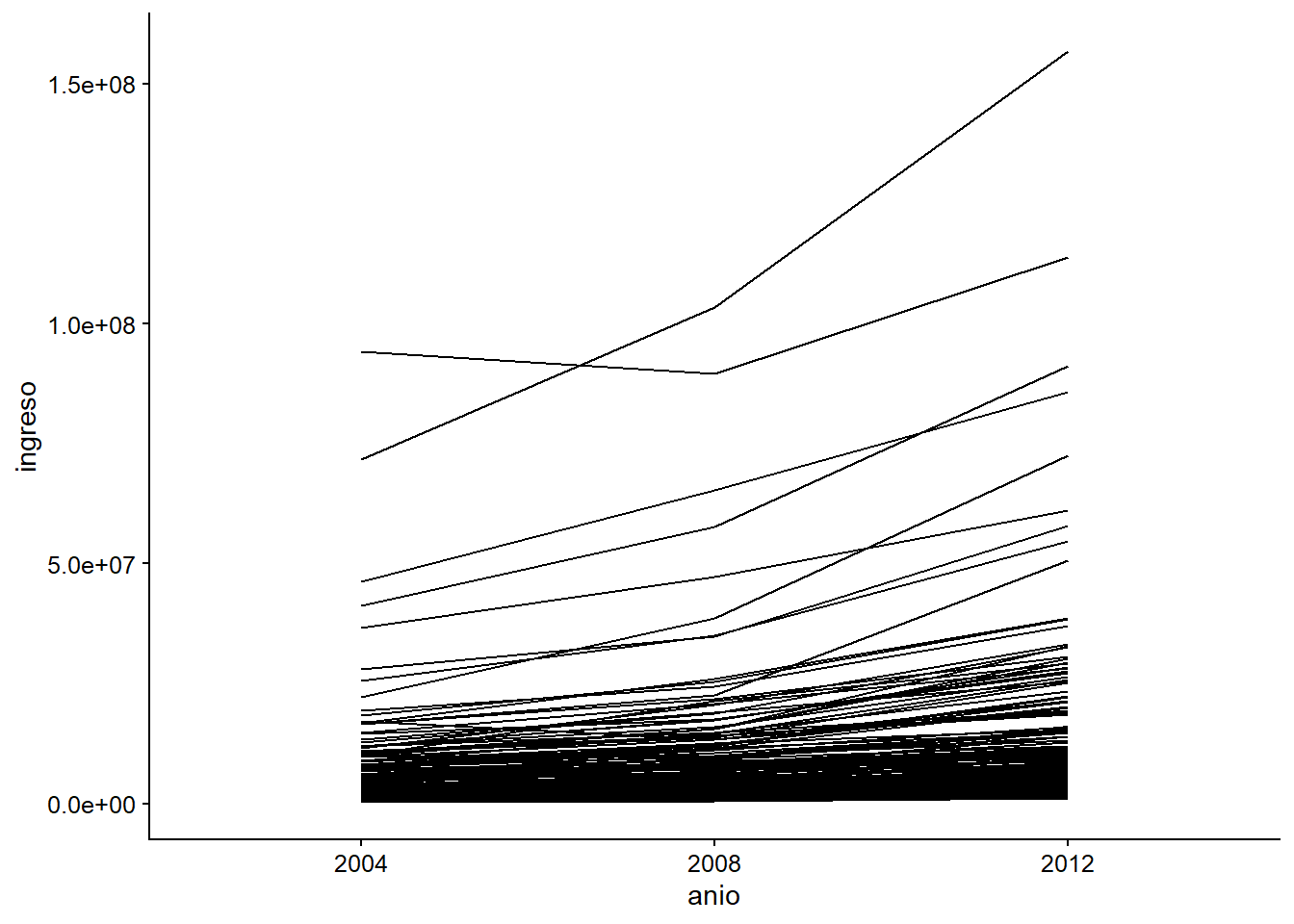
Figura 3.16: Evolución anual de los ingresos por municipio.
Una de las cuestiones que surge a primera vista es que, teniendo en cuenta que Chile tiene 345 municipios, parece imposible mostrarlos todos en un solo gráfico.
Ahora, podemos separar el gráfico como lo hemos hecho antes. Se puede hacer por zonas o regiones, considerando sus intereses. Ya hemos visto resultados diferentes por zonas, por lo que valdría la pena ver los ingresos de la misma manera:
plot_b +
geom_line(aes(group = municipalidad)) +
facet_wrap(~zona, nrow = 1)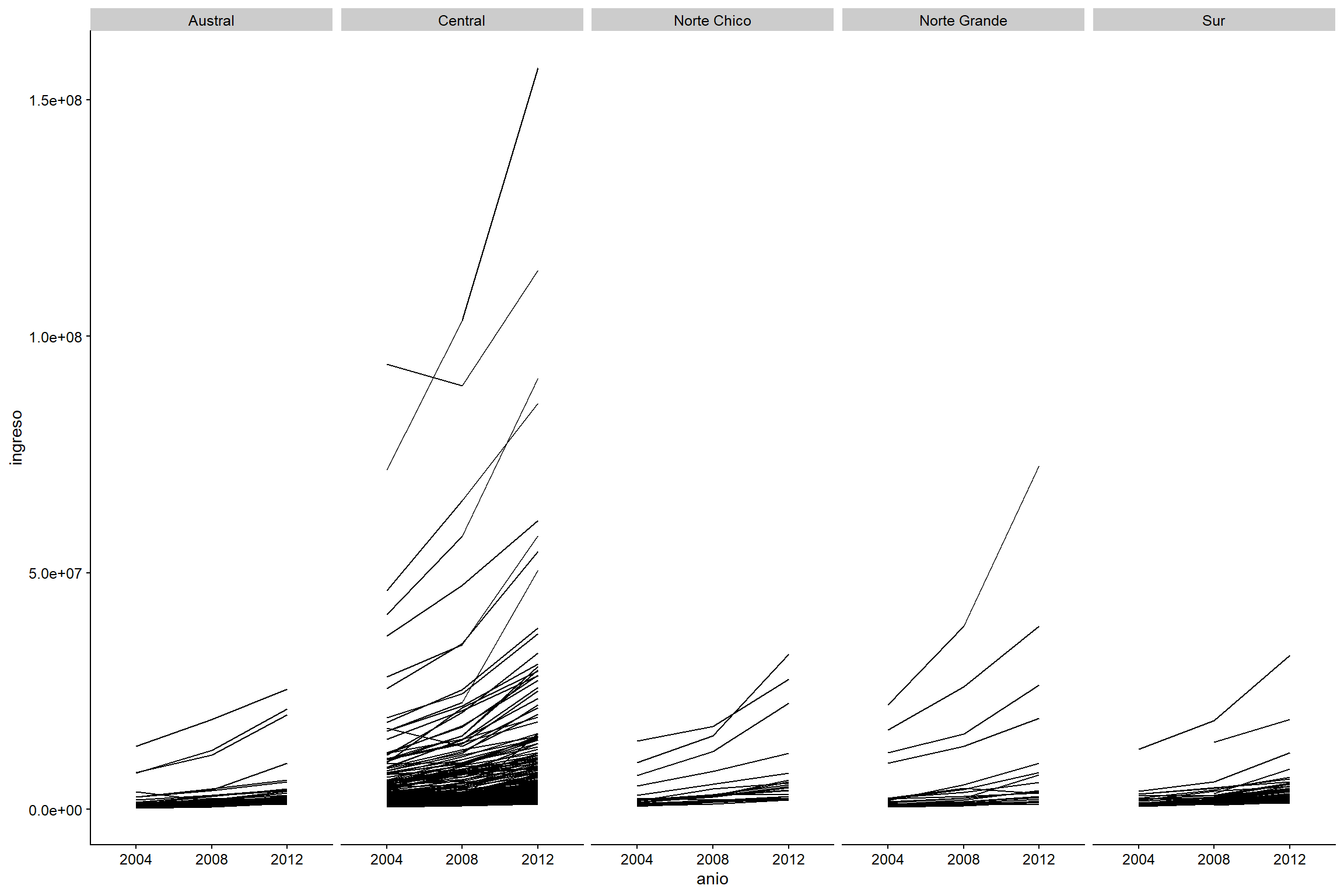
Figura 3.17: Evolución anual de los ingresos por municipio enfrentado por zona.
Como nuestra muestra se compone de un pequeño número de años, no podemos ver mucha variabilidad y, a primera vista, los ingresos de todos los municipios han aumentado considerablemente. Tal vez, todavía podemos hacer algunos ajustes a nuestro gráfico. Lo más probable es que no estés familiarizado con la notación científica y te resulte mejor leer números grandes. Tal vez sepas que es mejor trabajar con una variable monetaria en su transformación logarítmica, como nos han enseñado en diferentes cursos de metodología. Además, puede que quieras añadir otro tipo de información en este gráfico, por ejemplo, los promedios. ¿Qué piensas de este gráfico?
medias <- datos_municipales %>%
group_by(zona) %>%
summarize(media_ingreso = mean(ingreso, na.rm = T))
plot_b +
geom_line(color = "gray70", aes(group = municipalidad)) +
geom_hline(aes(yintercept = media_ingreso),
data = medias, color = "dodgerblue3") +
scale_x_discrete(expand = c(0,0)) +
scale_y_log10(labels = scales::dollar) +
facet_wrap(~ zona, nrow = 1) +
labs(title = " Ingresos municipales en los años electorales (2004-2012)",
y = " Ingresos",
x = "Año") +
theme(panel.spacing = unit(2, "lines"))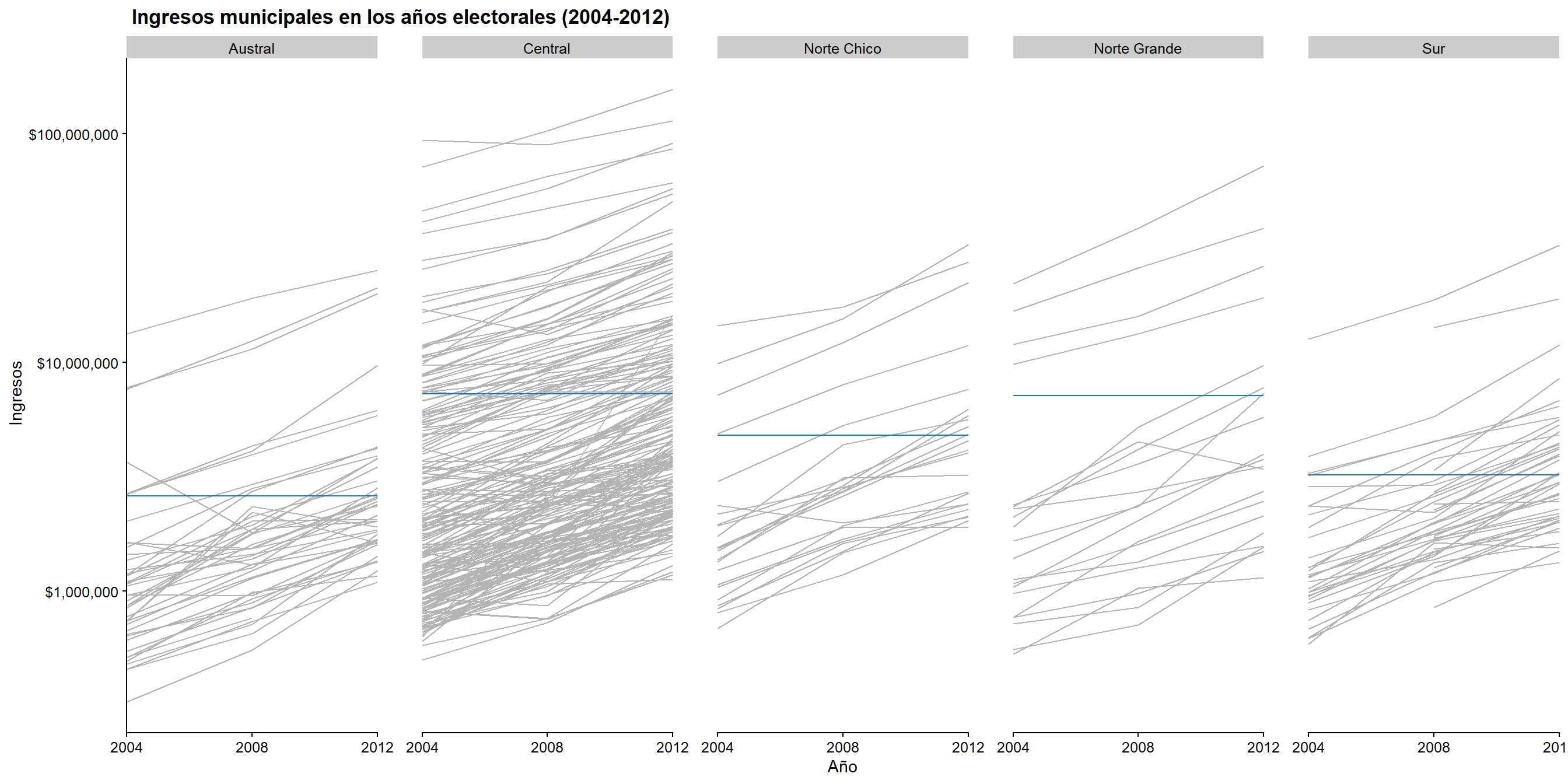
Figura 3.18: Versión completa de nuestro gráfico de líneas para los ingresos de los municipios en los años electorales.
¿Qué hemos especificado?
- Primero, creamos un conjunto de datos (“promedio”) que contiene los ingresos medios de cada zona. Lo hicimos usando
group_by()ysummarize()deltidyverse.
datos_municipales %>%
group_by(zona) %>%
summarize(media_ingreso = mean(ingreso, na.rm = T))
## # A tibble: 5 x 2
## zona media_ingreso
## <chr> <dbl>
## 1 Austral 2609648.
## 2 Central 7302625.
## 3 Norte Chico 4816249.
## # ... with 2 more rowsLuego, especificamos el color de la
geom_line().Después de eso, añadimos a nuestro código
geom_hline(). Este objeto geométrico, comogeom_vline()ogeom_abline(), nos permite añadir líneas con información. En este caso, lo usé para agregar el ingreso promedio de cada zona. Especificamos la variable que contiene la mediayintercept = mean, la base de datosmeans, y el color concolor = "dodgerblue3".A continuación, usamos
scale_x_discrete()para especificar la expansión de los paneles. Si antes veíamos un espacio gris sin información, lo eliminamos. Esto es estético.Luego, usamos
scale_x_discrete()para escalar nuestros datos. Esta es una transformación logarítmica que se hace normalmente cuando trabajamos con modelos lineales que contienen datos monetarios. Además, cambiamos las etiquetas del eje y: ya no aparece con notación científica. Esto se hizo con un paquete llamadoscales. Aquí llamamos a la función directamente conscales::dollar.Añadimos el título y los nombres de los ejes x e y con
labs().Finalmente, especificamos la información sobre el tema. Sin ella, los años entre un panel y otro se colapsarían. Para eso, lo especificamos con
panel.spacing = unit(2, "lines")en la capa detheme().
3.3.3 Gráfico de caja
Ya vimos que los ingresos de los municipios en Chile aumentaron entre 2004 y 2012. Si bien miramos el gráfico sin transformaciones funcionales, observamos que algunos municipios tenían ingresos muy superiores al promedio y se destacaban dentro de sus zonas. La intuición es que probablemente son extravagantes. Pudimos verlo claramente con un gráfico de caja, que nos permite graficar diversos datos descriptivos en nuestras variables como la mediana, el mínimo y el máximo. En este caso, lo utilizaremos para observar si nuestra intuición es correcta o no14.
Comencemos filtrando los datos como lo hicimos en el gráfico anterior. En nuestro eje x colocaremos las zonas de Chile y en el eje y los ingresos:
plot_c <- ggplot(data = datos_municipales %>%
filter(anio %in% c(2004, 2008, 2012)),
mapping = aes(x = zona, y = ingreso, color = zona)) +
geom_boxplot() +
facet_wrap(~anio, ncol = 1)
plot_c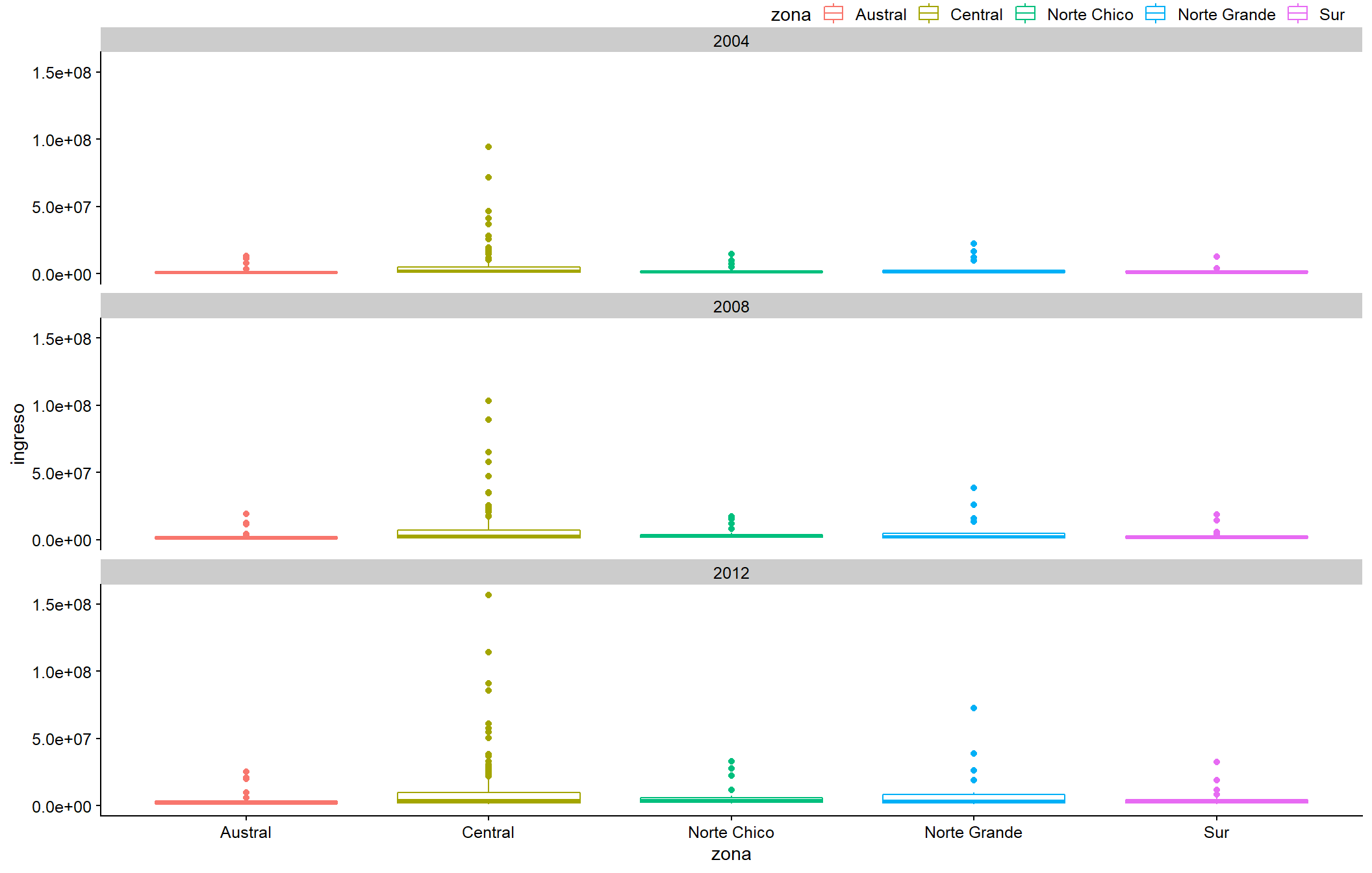
Figura 3.19: Recuadro de ingresos del municipio por zona, facetado por año.
Podemos ver valores atípicos muy claros. Tal vez, luego de mirar estos resultados, nos gustaría identificar qué municipalidades tienen mayores ingreso. Para esto podemos usar el mapeo estético label =, parte de geom_text(). Para etiquetas solo para los valores atípicos, debemos hacer un filtro en nuestra base:
plot_c +
geom_text(data = municipal_data %>% filter(income > 50000000),
mapping = aes(label = municipality))Desafortunadamente, las etiquetas están sobre los puntos y, en algunos casos, estos se superponen cuando están cerca uno del otro. Podemos resolver esto con el paquete ggrepel, que tiene un elemento geométrico geom_text() “mejorado” que evita la coalición de las etiquetas:
library(ggrepel)
plot_c +
geom_text_repel(data = datos_municipales %>%
filter(ingreso > 50000000),
mapping = aes(label = municipalidad))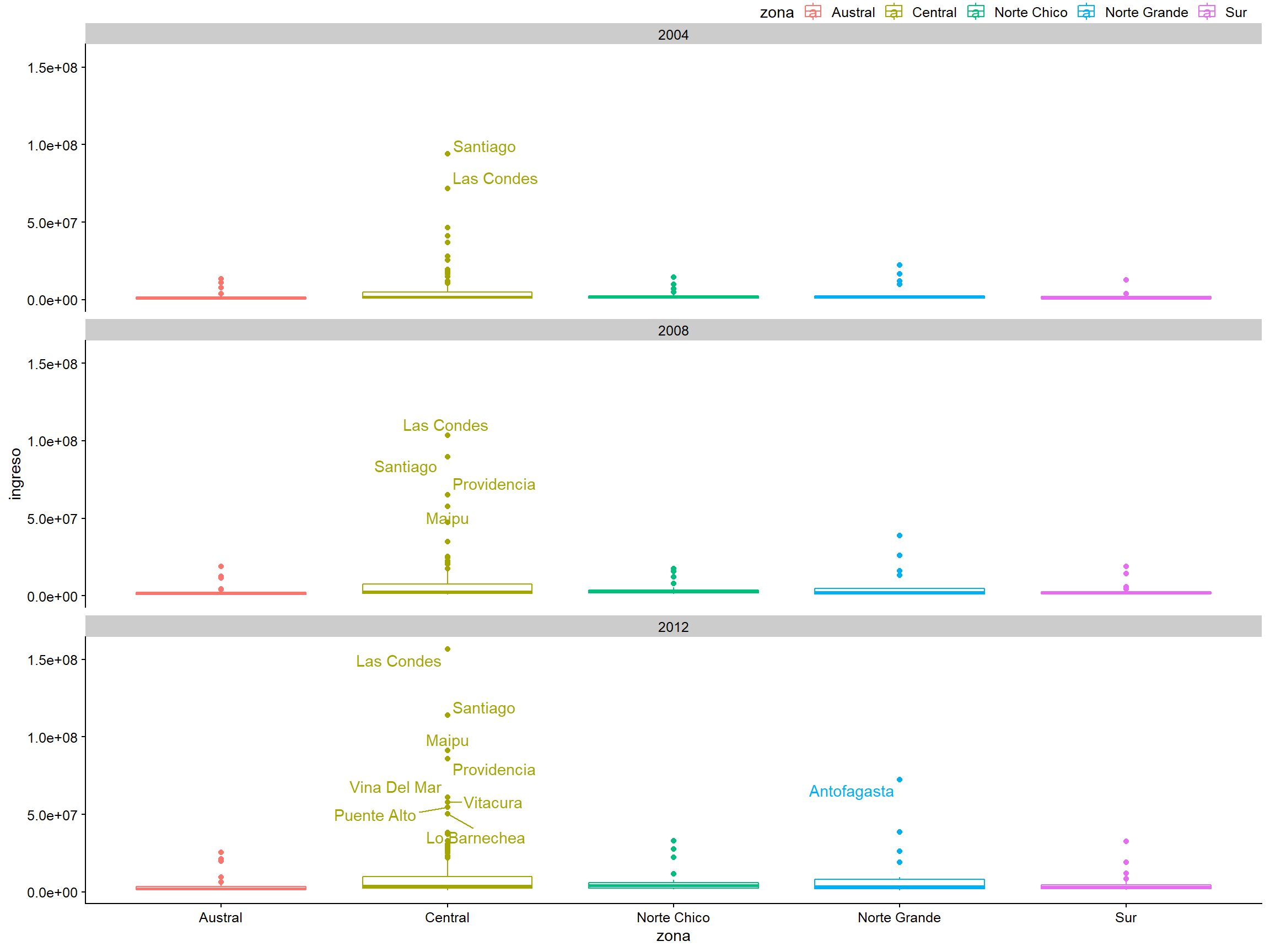
Figura 3.20: Podemos arreglar las etiquetas que se superponen usando el ggrepel.
El límite puede estar en 50.000.000 de dólares o en números mayores o menores. Depende enteramente de lo que queramos observar. Además, con geom_text o geom_text_repel no sólo podemos cambiar el color, sino también el tipo de fuente del texto, o si debe estar en negrita, cursiva o subrayado. Para ver más opciones, puedes escribir ?geom_text o llamar a un help("geom_text").
También podríamos añadir otra información o cambiar la forma en que se presenta actualmente el gráfico.
plot_c +
coord_flip() +
geom_text_repel(data = datos_municipales %>%
filter(ingreso > 50000000),
mapping = aes(label = municipalidad),
color = "black",
size = 3) +
scale_y_continuous(labels = scales::dollar) +
labs(title = "Ingresos municipales por zona (2004-2012)",
x = "Ingresos", y = "Zona",
caption = " Fuente: Basado en datos del SINIM (2018)")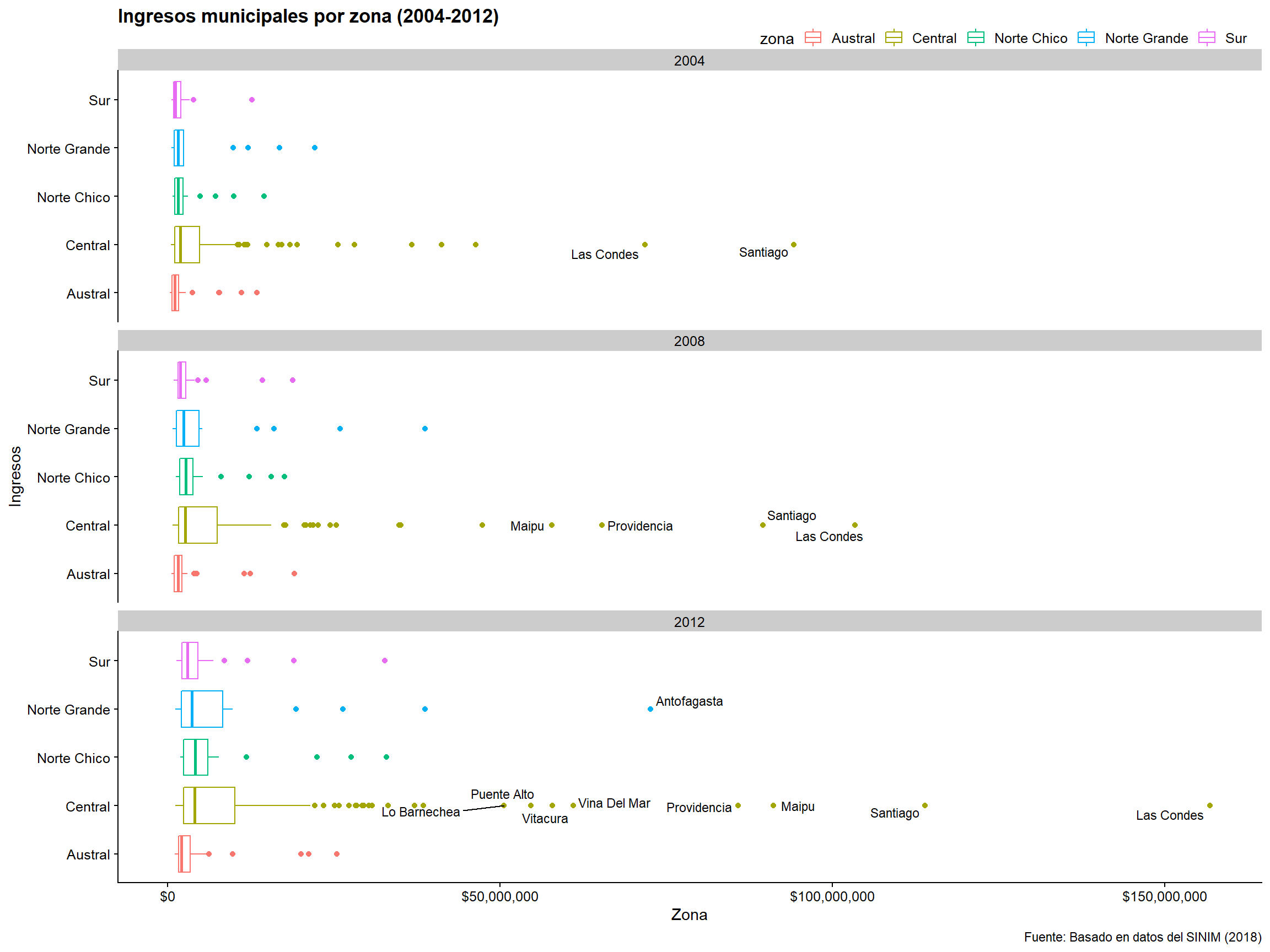
Figura 3.21: La versión pulida de nuestra gráfica de caja.
Algunas otras especificaciones:
- Hemos añadido la información descriptiva en el gráfico.
- Cambiamos el tamaño de la fuente. Esto era importante debido a la cantidad de municipios que están por encima de 50.000.000 dólares de ingresos.
- De nuevo, cambiamos las etiquetas del eje y con
scales::dollar. - Por último, con
guides, y especificando lasaes()que queríamos dirigir, escribimos el códigocolor=Fpara eliminar la etiqueta, ya que era información repetida dentro del gráfico.
Ejercicio 3A. Te invitamos a jugar con
geom_text: cambiar los colores, el tamaño, las fuentes, etcétera. También te animamos a instalar paquetes que te permitan personalizar aún más tus gráficos:ggthemesde jrnorl tiene temas para gráficos de programas y revistas conocidas como Excel o The Economist. Por otro lado,hrbrthemesde hrbrmstr ha elaborado algunos temas minimalistas y elegantes que harán que todos tus gráficos se vean mejor. Si te gustan los colores, puedes consultar el paquetewespalettede karthik, una paleta cromática basada en las películas de Wes Anderson, o crear tus propias paletas basadas en imágenes concolorfindr. Puedes encontrar más sobre esto último en el siguiente link.
3.3.4 Histograma
Como observamos en nuestro boxplot, muchos municipios, especialmente los de la zona central, están muy por encima de la media de ingresos por zona. Podemos ver la distribución de estos datos a través de un histograma. Construir un histograma es una tarea fácil, y como se mencionó anteriormente, geom_histogram no tiene un eje y explícito, ya que cuenta la frecuencia de un evento dentro de un intervalo.
Al crear el histograma según nuestra intuición, el resultado es el siguiente:
ggplot(data = datos_municipales,
mapping = aes(x = ingreso)) +
geom_histogram()
## Warning: Removed 7 rows containing non-finite values (stat_bin).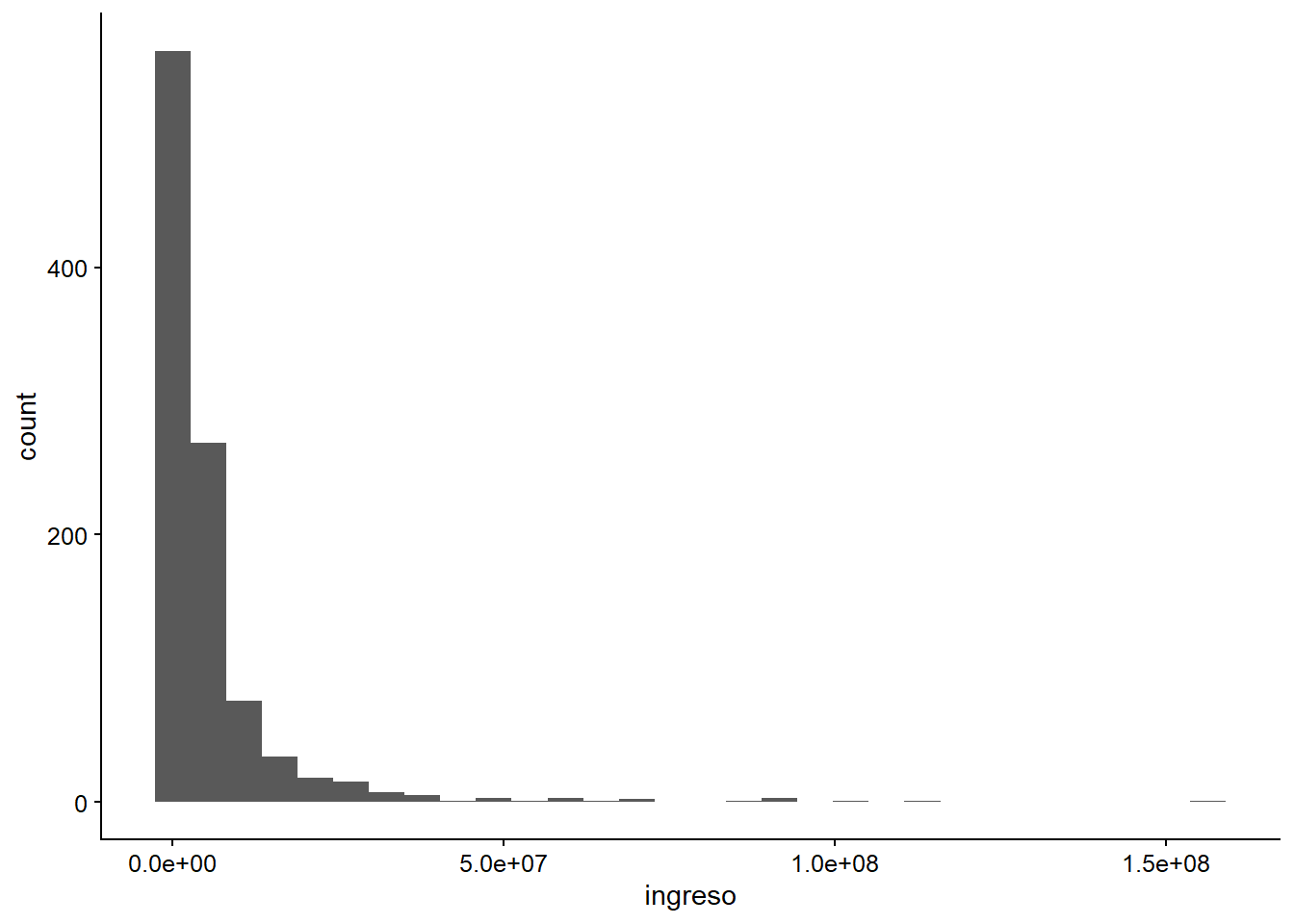
Figura 3.22: La versión más simple de un histograma de los ingresos fiscales del municipio.
Como podemos ver, el gráfico da una “Advertencia” que indica la existencia de “738 filas que contienen valores no finitos.” Esta advertencia ha estado presente a lo largo de todo este capítulo, y no significa nada más que “Hay valores desconocidos dentro de esta variable” y se debe a que no hay datos de los primeros años. Así que no te preocupes, si filtramos los datos con filter(!is.na(ingreso)), esta advertencia seguramente desaparecerá.
Además, la consola da el siguiente mensaje: stat_bin() usando bins = 30. Elija mejores valores con binwidth. Simplemente, dice que es posible modificar los intervalos para el histograma.
El siguiente paso es modificar el eje x. Personalmente, nunca he sido buena leyendo números con notación científica. Por otro lado, intentaremos cambiar el número de intervalos con bins.
ggplot(data = datos_municipales,
mapping = aes(x = ingreso)) +
geom_histogram(bins = 50) +
scale_x_continuous(labels = scales::dollar)
## Warning: Removed 7 rows containing non-finite values (stat_bin).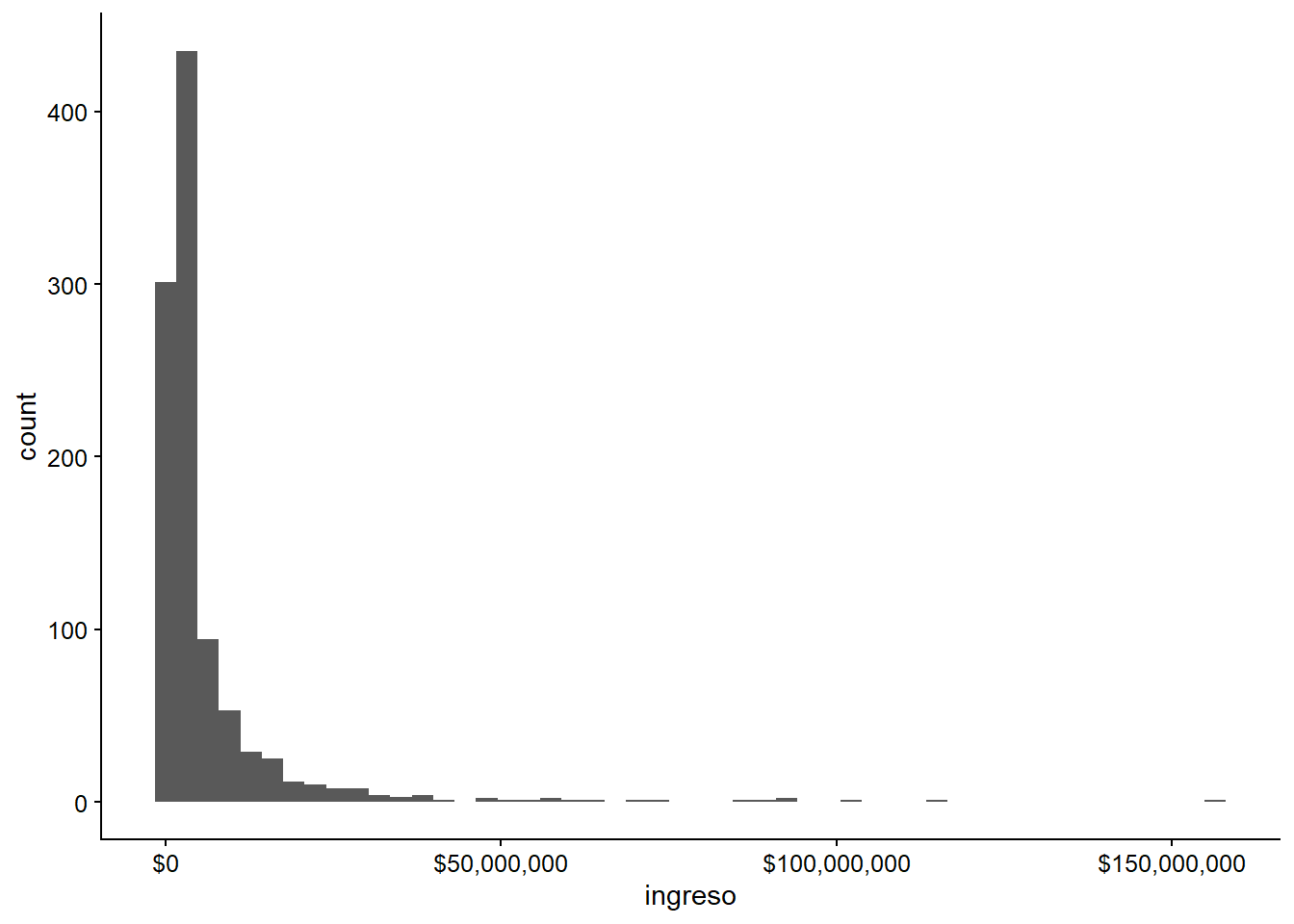
Figura 3.23: Histograma de los ingresos fiscales del municipio con una escala corregida en x.
Ejercicio 3B. ¿Qué pasa si ponemos
bins = 15de intervalos?
A continuación haremos un subconjunto de los datos. Considerando el número de valores atípicos que encontramos, eliminaremos los municipios con ingresos superiores a 50.000.000 dólares. También podemos examinar la frecuencia por zona. Como cuando usamos color con geom_boxplot, usaremos fill con geom_histogram.
ggplot(data = datos_municipales %>% filter(ingreso < 50000000),
mapping = aes(x = ingreso, fill = zona)) +
geom_histogram(alpha = 0.5, bins = 50) +
scale_x_continuous(labels = scales::dollar) +
labs(title = "Número de municipios según sus ingresos anuales
(2004-2012)",
x = "Ingreso", y = " Número de municipios",
caption = " Fuente: Basado en los datos del SINIM (2018)")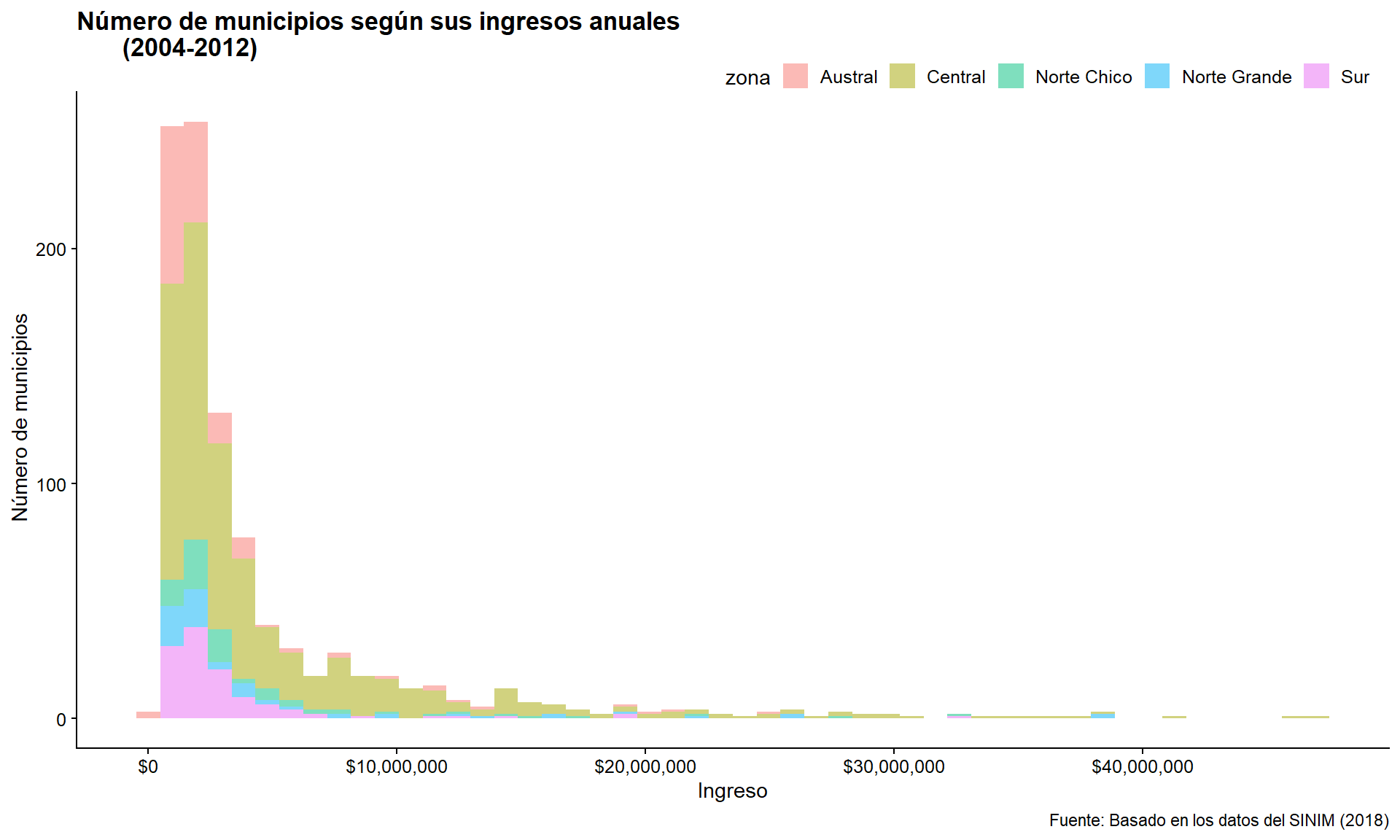
Figura 3.24: Versión pulida de nuestro histograma en el que haremos ‘fill’ por zona.
3.3.5 Relación entre las variables
Es probable que una de tus mayores preocupaciones sea si las dos variables que estás estudiando están relacionadas de alguna manera. Con ggplot2 esto es fácil de verificar. En este caso, tenemos dos variables continuas: la tasa de pobreza, del conjunto de datos de CASEN, y los ingresos municipales. Siguiendo la teoría, debería haber algún tipo de correlación: cuanto mayor sea el ingreso municipal, menor será la tasa de pobreza en el municipio. Creamos nuestros datos:
plot_f <- ggplot(data = datos_municipales,
mapping = aes(x = pobreza, y = log(ingreso)))Para este tipo de gráfico, usaremosgeom_smooth. Con este objeto, puedes modificar la forma en que las variables se relacionan con method. También puedes introducir tus propias fórmulas. Por defecto, se especifica una relación lineal entre las variables, por lo que no es necesario escribirla.
plot_f +
geom_smooth(method = "lm", color = "dodgerblue3") 
Figura 3.25: Ajuste lineal de la pobreza en el log de ingresos.
Parece vacía, ¿no? Normalmente, usamos geom_smooth con otras figuras geométricas, como geom_point, para indicar la posición de las columnas en el espacio. Usamos alpha para ver la superposición de los puntos. Como no son demasiados, no hay problemas para ver cómo se distribuyen.
plot_f +
geom_point(alpha = 0.3) +
geom_smooth(method = "lm", color = "dodgerblue3") 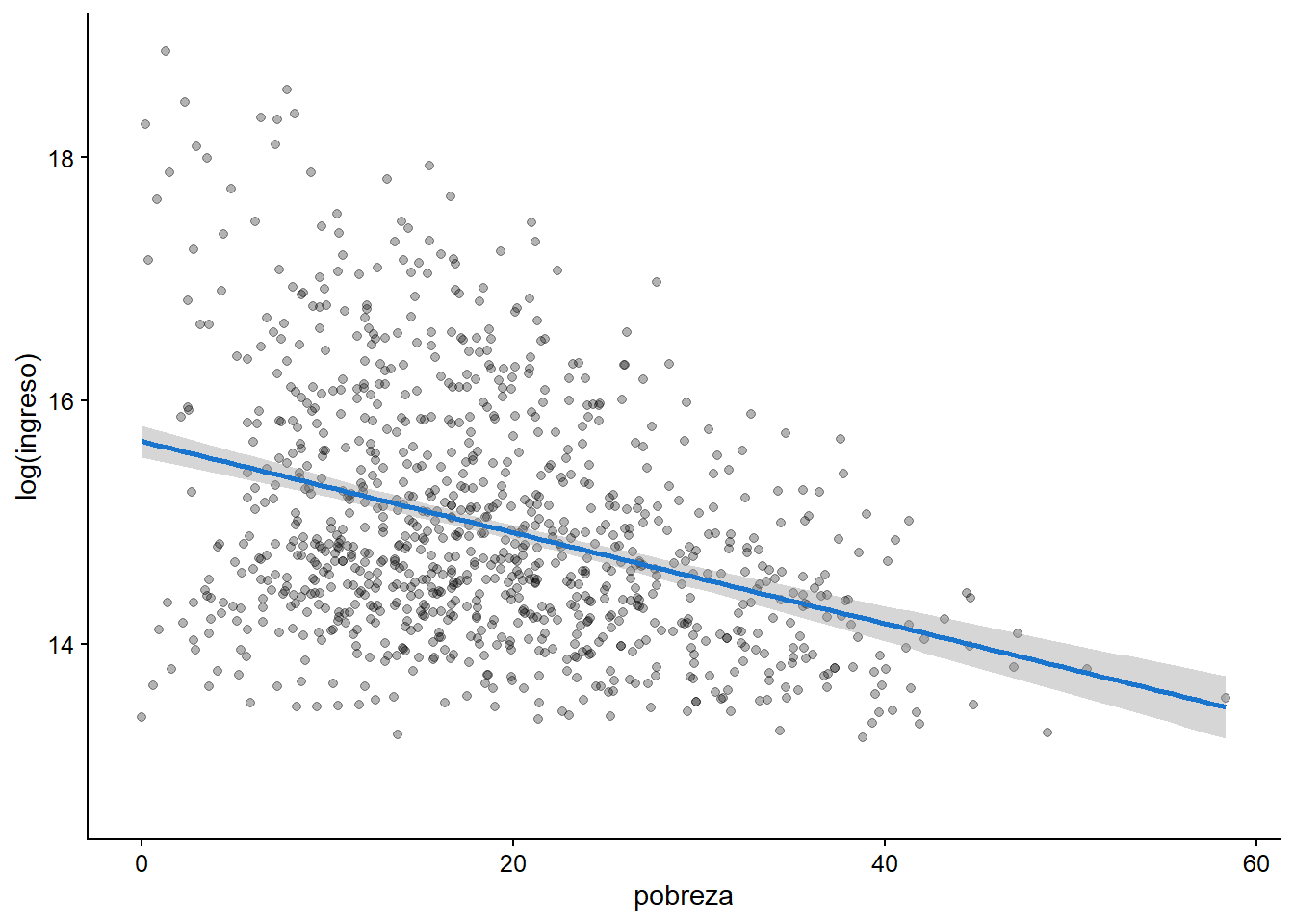
Figura 3.26: El ajuste lineal más las observaciones dispersas.
Ahora podemos hacer dos mejoras. Primero, insertaremos el título y el nombre de los ejes. Segundo, en geom_x_continuous especificaremos donde empieza y acaba nuestra gráfica. Ya habíamos usado esto con geom_line.
plot_f +
geom_point(alpha = 0.3) +
geom_smooth(method = "lm", color = "dodgerblue3") +
scale_x_continuous(expand = c(0,0)) +
labs(title = " Relación entre los ingresos del municipio y la tasa de pobreza de
CASEN, Chile (2004-2012)",
x = "Tasa de pobreza de CASEN", y = " Ingresos",
caption = " Fuente: Basado en los datos del SINIM (2018)") 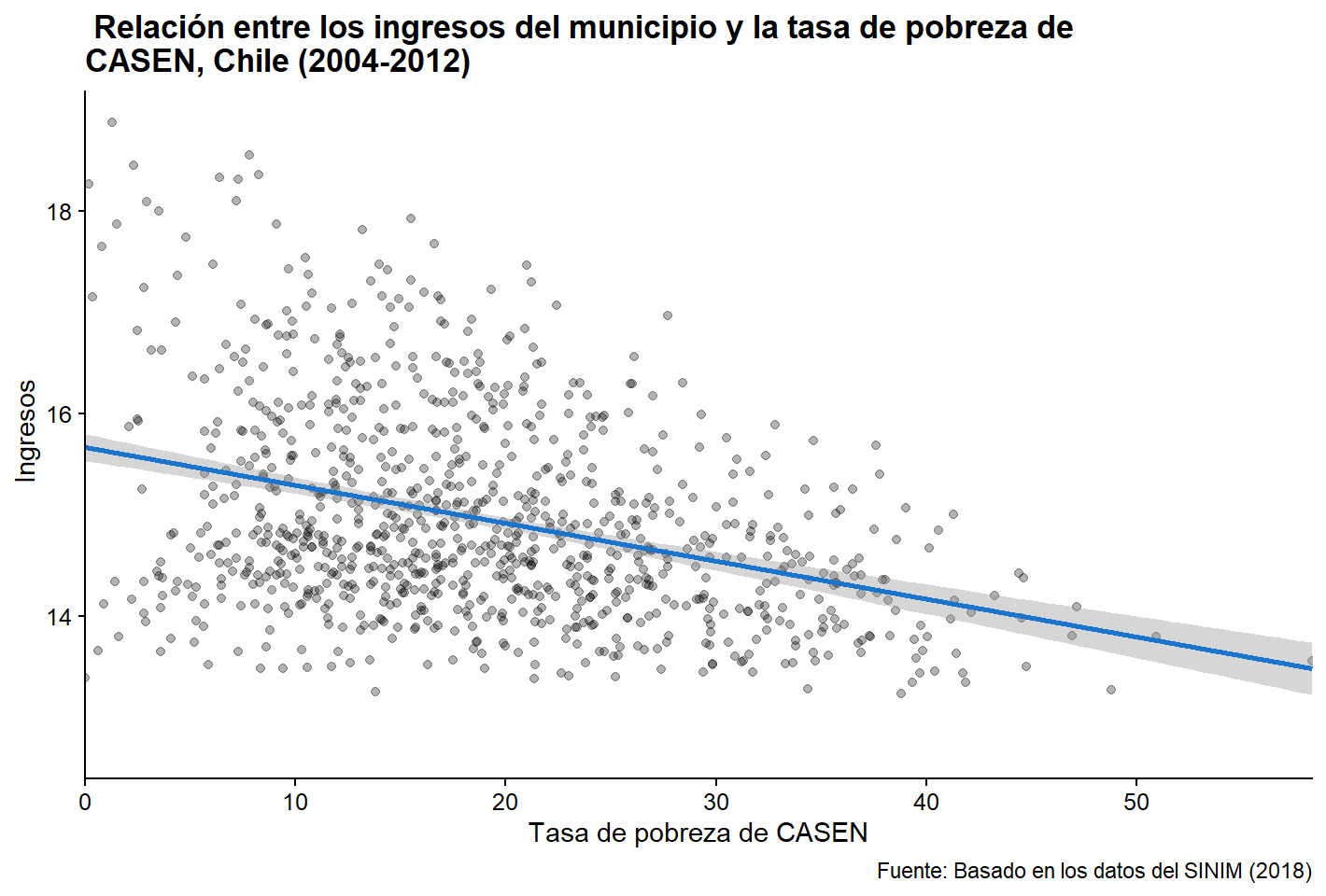
Figura 3.27: La versión pulida de nuestra gráfica de ajuste lineal.
Claramente, hay una correlación negativa entre ambas variables. ¡Esto es lo que esperábamos! Ahora, podemos calcular la correlación entre ambas variables, para estar más seguros de los resultados obtenidos visualmente:
cor(datos_municipales $pobreza, datos_municipales$ingreso,
use = "pairwise.complete.obs")
## [1] -0.27La correlación entre ambas variables es de -0,27. Sería interesante añadir esta información en el gráfico. Podemos hacer esto con annotate(). Sólo necesitamos especificar el tipo de objeto geométrico que queremos generar. En este caso, lo que queremos crear es el texto geom = "text", pero podría ser una caja que resalte un punto específico en el gráfico geom = "rect" o una línea geom = "segment". Especificamos dónde queremos ubicarlo y, finalmente, anotamos lo que queremos anotar.
plot_f +
geom_point(alpha = 0.3) +
geom_smooth(method = "lm", color = "dodgerblue3") +
scale_x_continuous(expand = c(0, 0)) +
labs(
title = " Relación entre los ingresos del municipio y la tasa de pobreza de
CASEN, Chile (2004-2012)",
x = "Tasa de pobreza de CASEN ", y = " Ingresos",
caption = " Fuente: Basado en los datos del SINIM (2018)") +
annotate("text", x = 50, y = 15, label = "Correlación:\n-0.27")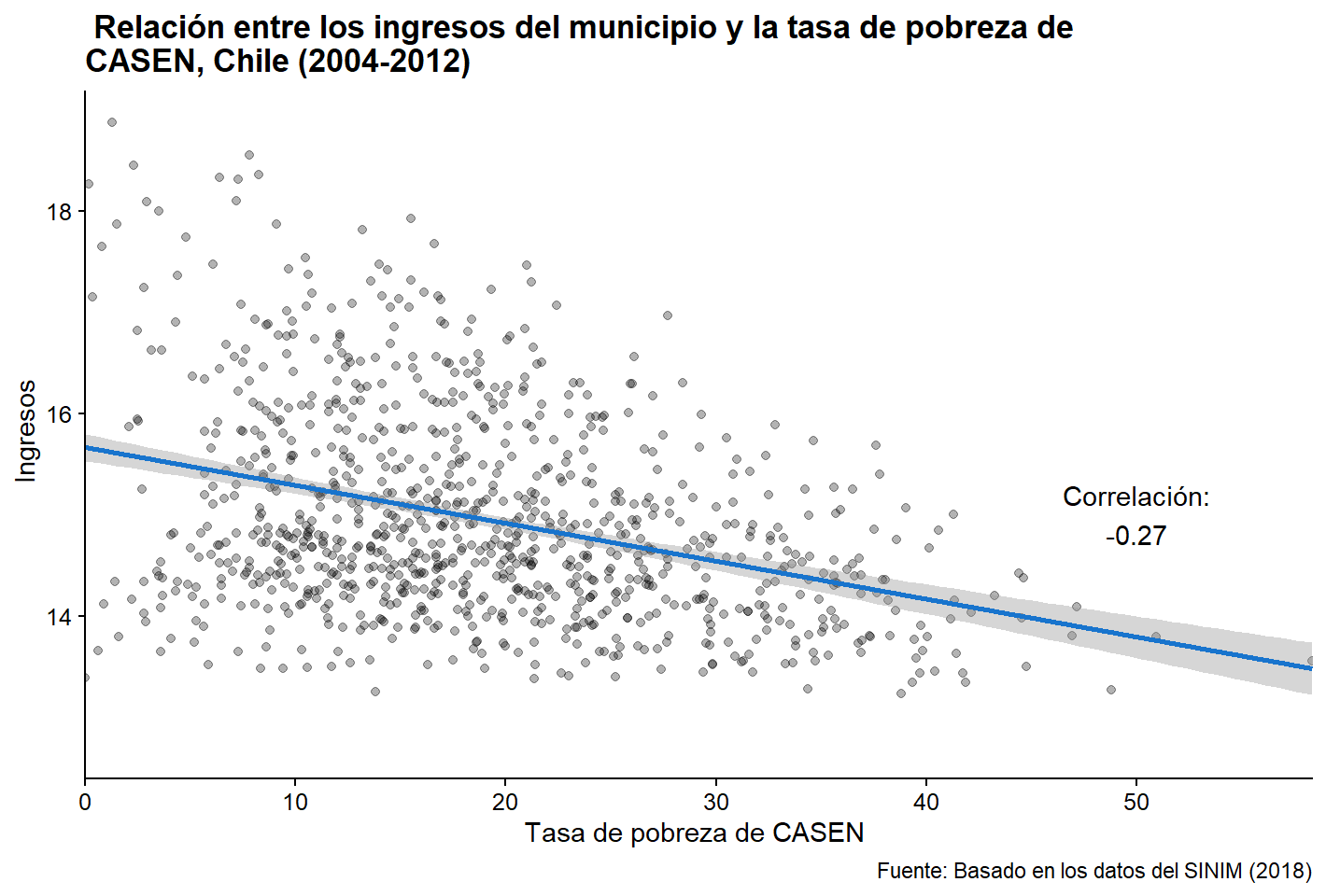
Figura 3.28: Añadimos la coeficiente de correlación usando annotate.
3.4 Para continuar aprendiendo
Hay muchos caminos para visualizar sus datos. En este capítulo, aprendiste las principales funciones de ggplot2, un paquete dentro de tidyverse, pero hay muchos más paquetes que pueden ser de gran ayuda para otros tipos de visualizaciones. Aunque ggplot2 puede no tener todos los objetos geométricos que necesitas, hay paquetes para visualizar otros tipos de datos que funcionan bajo ggplot2 y las capas que constituyen su estructura “gramatical.”
### Otros paquetes:
3.4.0.1 sf
Permite visualizar elementos espaciales. Para ggplot2 funciona con geom_sf. Permite la creación de figuras geométricas con diferentes tipos de datos espaciales. En el capítulo 16 de datos espaciales, Andrea y Gabriel entregan las herramientas para trabajar con sf, sus principales funciones y directrices. Aquí puede encontrar más detalles sobre cómo instalarlo y su rendimiento dependiendo de su ordenador.
3.4.0.2 ggparliament
Todos los politólogos deberían conocer este paquete. Permite visualizar la composición del poder legislativo. Es un sueño para aquellos que trabajan con este tipo de información. Te permite especificar el número de escaños, el color de cada partido, y añadir diferentes características a tu gráfico. Aquí puedes encontrar más detalles sobre las herramientas de ggparliament.
![Ejemplo de una gráfica construida con ggparliament con datos del Parlamento Mexicano.^[Source: (“@leonugo,” Twitter)[https://twitter.com/leonugo/status/1014298553500479489?lang=es]](00-images/dataviz/tweet_ggparl.png)
Figura 3.29: Ejemplo de una gráfica construida con ggparliament con datos del Parlamento Mexicano.^[Source: (“@leonugo,” Twitter)[https://twitter.com/leonugo/status/1014298553500479489?lang=es]
3.4.0.3 ggraph
Si estudias redes y sabes cómo funciona ggplot2, este paquete puede convertirse en tu nuevo mejor amigo. Está hecho para todo tipo de datos relacionales, y aunque funciona bajo la lógica de ggplot2, tiene sus propios objetos geométricos, facetas, entre otros. Aquí puedes encontrar más información. El Capítulo 14 te mostrará cómo usar este paquete en profundidad.
3.4.0.4 patchwork
Esta es una gran herramienta para combinar diferentes ggplots en el mismo gráfico. Usarás +, | y / para organizarlos.
library(patchwork)
(plot_f | plot_b) / plot_c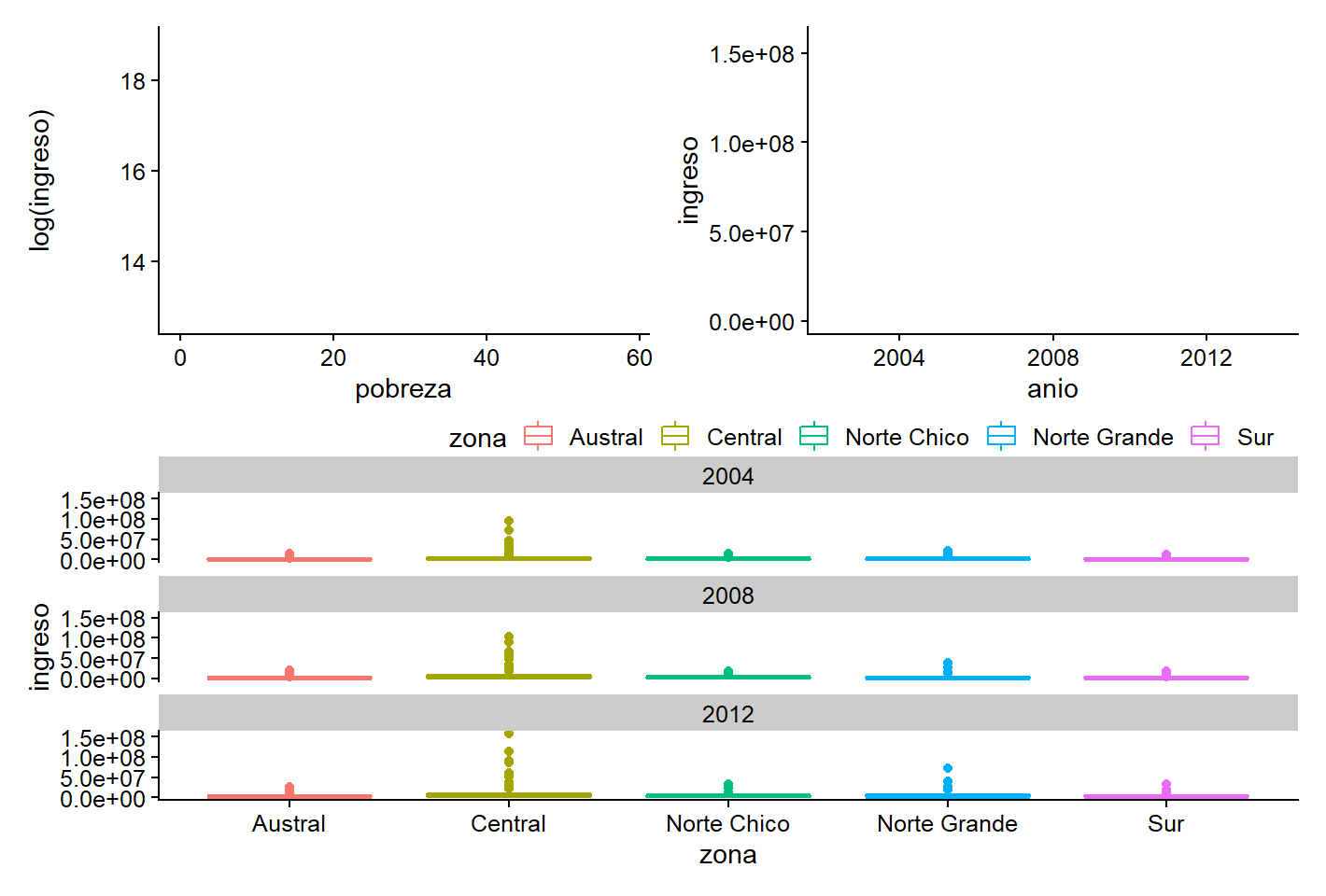
Figura 3.30: Ejemplo de patchwork.
Ejercicio 3C. Ya hemos aprendido a hacer un histograma, sin embargo, los gráficos de densidad tienden a ser más utilizados para mirar la distribución de una variable. Usando las mismas variables, haz una gráfica de densidad con
geom_density().Ejercicio 3D. Normalmente, los gráficos de barras se presentan con la frecuencia o proporción dentro de la barra. También podemos hacer esto con el
ggplot2. Usandogeom_bar()ygeom_text(), apunta el número de alcaldes por área geográfica. Un consejo: tienes que hacer algunos cálculos contidyverseantes de añadir esa información en la gráfica.Ejercicio 3E. Escogiendo solo un año, haz un gráfico de líneas con
geom_smooth()que indique la relación entre los ingresos y la tasa de pobreza. Ahora, conannotate(), haz ungráfico de caja que contenga los municipios con mayor índice de pobreza y, encima de él, escribe el nombre del municipio correspondiente.
E-mail: snaraya@uc.cl↩︎
Aun así, siempre es entretenido observar cómo existe una correlación entre el consumo de queso per cápita y el número de personas estranguladas hasta la muerte por sus sábanas en los Estados Unidos!↩︎
El capítulo 16 será muy útil si desea detectar los valores atípicos a través de los mapas↩︎