05A - Manejo avanzado de datos
Si quieres correr estos scripts localmente, acá puedes descargar el proyecto comprimido en .zip. Paquetes que necesitas tener instalados antes de comenzar con el proyecto (05A, 05B):
tidyverse,janitor.
Inicio: cargar paquetes, base de datos
## Parsed with column specification:
## cols(
## comuna = col_character(),
## comuna_id = col_double(),
## `2012` = col_double(),
## `2013` = col_double(),
## `2014` = col_double(),
## `2015` = col_double(),
## `2016` = col_double()
## )Tenemos una base de datos con los casos policiales de robos cada 1.000 habitantes. Contiene información para 340 comunas de Chile, 2012-2016. Su fuente es la Subsecretaría de Prevención del Delito (2017).
Pivotear bases de datos (wide <-> long)
¿Qué pasa si queremos graficar estos datos, por ejemplo viendo la evolución temporal de la variable en una comuna? El formato de los datos no es el ideal. Aquí los valores de una variable (año) se expandieron hacia las columnas, generando una base en formato wide.
Podemos “alargar” esta base usando la función pivot_longer(), de la siguiente manera:
df_tasa_robos_long <- df_tasa_robos %>%
pivot_longer(cols = -c(comuna, comuna_id), # descartamos vars. que no queremos transformar
names_to = "anio", values_to = "tasa_robos")
df_tasa_robos_long## # A tibble: 1,700 x 4
## comuna comuna_id anio tasa_robos
## <chr> <dbl> <chr> <dbl>
## 1 Algarrobo 5602 2012 4031.
## 2 Algarrobo 5602 2013 3612.
## 3 Algarrobo 5602 2014 3734.
## 4 Algarrobo 5602 2015 4231.
## 5 Algarrobo 5602 2016 3665.
## 6 Alhué 13502 2012 796.
## 7 Alhué 13502 2013 950.
## 8 Alhué 13502 2014 1167.
## 9 Alhué 13502 2015 606.
## 10 Alhué 13502 2016 956.
## # ... with 1,690 more rowsEsta estructura de datos es mucho más amigable para ggplot2:
ggplot(data = df_tasa_robos_long %>% filter(comuna %in% c("San-Joaquín", "Macul")),
mapping = aes(x = as.factor(anio), y = tasa_robos,
color = comuna, group = comuna)) +
geom_line() # podríamos seguir añadiendo escalas, labs, etc...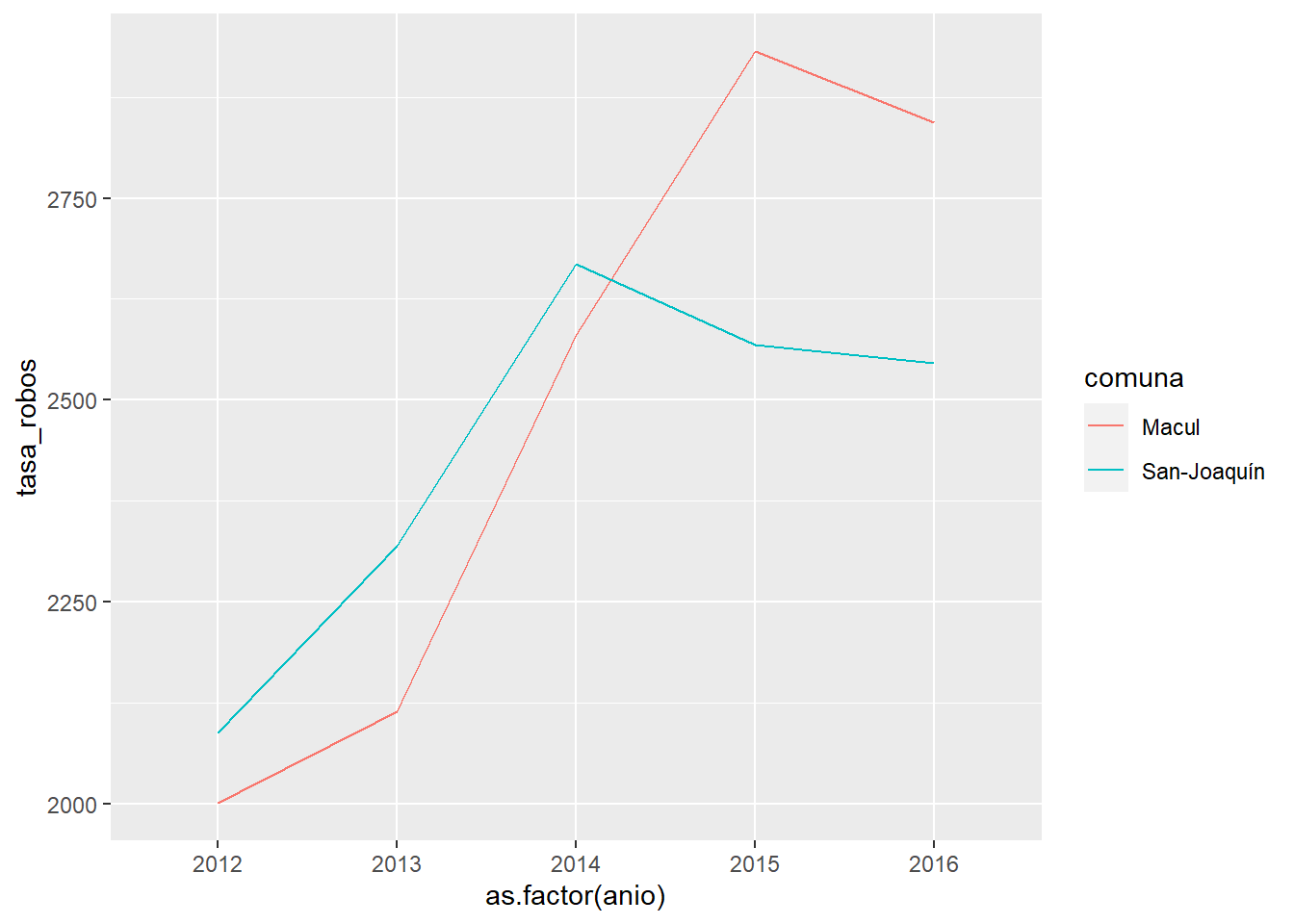
Noten que pivot_longer() tiene una función recíproca, pivot_wider():
## # A tibble: 340 x 7
## comuna comuna_id `2012` `2013` `2014` `2015` `2016`
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Algarrobo 5602 4031. 3612. 3734. 4231. 3665.
## 2 Alhué 13502 796. 950. 1167. 606. 956.
## 3 Alto-Biobío 8314 225. 305. 245. 139. 103.
## 4 Alto-del-Carmen 3302 208. 209. 397. 293. 315.
## 5 Alto-Hospicio 1107 2589. 2218. 1930. 1962. 1847.
## 6 Ancud 10202 579. 763. 697. 755. 732.
## 7 Andacollo 4103 759. 640. 892. 911. 1075.
## 8 Angol 9201 1400. 1515. 1822. 1939. 1468.
## 9 Antártica 12202 0 0 0 0 0
## 10 Antofagasta 2101 2178. 1892. 1938. 1671. 1391.
## # ... with 330 more rowsRecodificar variables
Supongamos que, usando nuestra nueva base long, queremos crear una variable binaria/dummy que indique si la observación es para el gobierno de Piñera I o Bachelet II. Podemos usar if_else() dentro de mutate():
df_tasa_robos_long %>%
mutate(d_gob_bachelet = if_else(condition = anio >= 2014,
true = 1,
false = 0))## # A tibble: 1,700 x 5
## comuna comuna_id anio tasa_robos d_gob_bachelet
## <chr> <dbl> <chr> <dbl> <dbl>
## 1 Algarrobo 5602 2012 4031. 0
## 2 Algarrobo 5602 2013 3612. 0
## 3 Algarrobo 5602 2014 3734. 1
## 4 Algarrobo 5602 2015 4231. 1
## 5 Algarrobo 5602 2016 3665. 1
## 6 Alhué 13502 2012 796. 0
## 7 Alhué 13502 2013 950. 0
## 8 Alhué 13502 2014 1167. 1
## 9 Alhué 13502 2015 606. 1
## 10 Alhué 13502 2016 956. 1
## # ... with 1,690 more rowsif_else() nos sirve si es que queremos crear variables binarias (numéricas o no). Pero a menudo queremos asignar más categorías. En esos casos podemos usar case_when():
df_tasa_robos_long %>%
mutate(gobierno = case_when(anio < 2014 ~ "Piñera I", # condición ~ valor
anio == 2014 ~ "Cambio de mando",
anio > 2014 ~ "Bachelet II"))## # A tibble: 1,700 x 5
## comuna comuna_id anio tasa_robos gobierno
## <chr> <dbl> <chr> <dbl> <chr>
## 1 Algarrobo 5602 2012 4031. Piñera I
## 2 Algarrobo 5602 2013 3612. Piñera I
## 3 Algarrobo 5602 2014 3734. Cambio de mando
## 4 Algarrobo 5602 2015 4231. Bachelet II
## 5 Algarrobo 5602 2016 3665. Bachelet II
## 6 Alhué 13502 2012 796. Piñera I
## 7 Alhué 13502 2013 950. Piñera I
## 8 Alhué 13502 2014 1167. Cambio de mando
## 9 Alhué 13502 2015 606. Bachelet II
## 10 Alhué 13502 2016 956. Bachelet II
## # ... with 1,690 more rowsUna opción válida al usar case_when() es asignar un valor para “cualquier otro caso”:
df_tasa_robos_long %>%
mutate(gobierno = case_when(anio < 2014 ~ "Piñera I",
anio == 2014 ~ "Cambio de mando",
TRUE ~ "Bachelet II")) # en cualquier otro caso## # A tibble: 1,700 x 5
## comuna comuna_id anio tasa_robos gobierno
## <chr> <dbl> <chr> <dbl> <chr>
## 1 Algarrobo 5602 2012 4031. Piñera I
## 2 Algarrobo 5602 2013 3612. Piñera I
## 3 Algarrobo 5602 2014 3734. Cambio de mando
## 4 Algarrobo 5602 2015 4231. Bachelet II
## 5 Algarrobo 5602 2016 3665. Bachelet II
## 6 Alhué 13502 2012 796. Piñera I
## 7 Alhué 13502 2013 950. Piñera I
## 8 Alhué 13502 2014 1167. Cambio de mando
## 9 Alhué 13502 2015 606. Bachelet II
## 10 Alhué 13502 2016 956. Bachelet II
## # ... with 1,690 more rowsMini-ejercicio
Crea la variable d_gob_bachele de antes, pero esta vez usando case_when(). Tu código:
Valores perdidos/missing/NA
Para el resto de la clase trabajaremos también con datos de robos, esta vez para los países del Cono Sur (2006-2016). La fuente es la Oficina de las Naciones Unidas contra la Droga y el Delito (UNODC).
## Parsed with column specification:
## cols(
## pais = col_character(),
## pais_codigo = col_character(),
## anio = col_double(),
## robos_c100k = col_double()
## )## # A tibble: 33 x 4
## pais pais_codigo anio robos_c100k
## <chr> <chr> <dbl> <dbl>
## 1 Argentina ARG 2006 738.
## 2 Argentina ARG 2007 662.
## 3 Argentina ARG 2008 704.
## 4 Argentina ARG 2009 NA
## 5 Argentina ARG 2010 NA
## 6 Argentina ARG 2011 NA
## 7 Argentina ARG 2012 NA
## 8 Argentina ARG 2013 NA
## 9 Argentina ARG 2014 668.
## 10 Argentina ARG 2015 626.
## # ... with 23 more rowsVeamos los datos. ¿Qué pasó con las datos de Argentina, 2009-2013?
R registra los valores perdidos como “NA”. Esto no es un caracter con las letras N y A, sino que un valor especial dentro del vector, sin importar su tipo.
Realizar operaciones básicas en vectores con NA
Intentemos calcular la media por país para la variable “robos_c100k”:
## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## pais media_robos_c100k
## <chr> <dbl>
## 1 Argentina NA
## 2 Chile 1070.
## 3 Uruguay 2984.La mayoría de las operaciones básicas en R (median(), sd(), sum(), etc.) fallarán cuando alguno de los valores en el cálculo sea un NA. Si es que de todas formas queremos utilizar la función, tomando en cuenta solo los valores existentes, prácticamente todas estas operaciones incluyen un argumento na.rm = (NA remove):
df_robos_cono_sur %>%
group_by(pais) %>%
summarize(media_robos_c100k = mean(robos_c100k, na.rm = T))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## pais media_robos_c100k
## <chr> <dbl>
## 1 Argentina 669.
## 2 Chile 1070.
## 3 Uruguay 2984.Por defecto, los modelos de regresión hacen algo como esto, omiten las observaciones que tengan NA en alguna de las variables del modelo. Siempre que estemos en la duda sobre cómo se comporta alguna función ante NAs, deberíamos revisar su archivo de ayuda y buscar algún argumento que incluya “na”:
Filtrar NAs de una base
Lo siguiente no funcionará:
Lo que debemos utilizar en operaciones lógicas para testear la presencia de NAs es la función is.na():
## # A tibble: 5 x 4
## pais pais_codigo anio robos_c100k
## <chr> <chr> <dbl> <dbl>
## 1 Argentina ARG 2009 NA
## 2 Argentina ARG 2010 NA
## 3 Argentina ARG 2011 NA
## 4 Argentina ARG 2012 NA
## 5 Argentina ARG 2013 NAPodemos realizar una negación en una operación lógica antecediéndola de un signo de exclamación. En este caso, obtendremos solo las observaciones que no tienen NA en “robos_c100k”:
## # A tibble: 28 x 4
## pais pais_codigo anio robos_c100k
## <chr> <chr> <dbl> <dbl>
## 1 Argentina ARG 2006 738.
## 2 Argentina ARG 2007 662.
## 3 Argentina ARG 2008 704.
## 4 Argentina ARG 2014 668.
## 5 Argentina ARG 2015 626.
## 6 Argentina ARG 2016 616.
## 7 Chile CHL 2006 942.
## 8 Chile CHL 2007 1018.
## 9 Chile CHL 2008 1054.
## 10 Chile CHL 2009 1136.
## # ... with 18 more rowsCrear valores perdidos
## # A tibble: 33 x 4
## pais pais_codigo anio robos_c100k
## <chr> <chr> <dbl> <dbl>
## 1 Argentina ARG 2006 738.
## 2 Argentina ARG 2007 662.
## 3 Argentina ARG 2008 704.
## 4 Argentina ARG 2009 NA
## 5 Argentina ARG 2010 NA
## 6 Argentina ARG 2011 NA
## 7 Argentina ARG 2012 NA
## 8 Argentina ARG 2013 NA
## 9 Argentina ARG 2014 668.
## 10 Argentina ARG 2015 626.
## # ... with 23 more rowsSupongamos que no confiamos en los datos más antiguos para Argentina (2006-2008) y también queremos asignarlos como valores perdidos. Una opción podría ser eliminar dichas observaciones con filter(), pero tal vez tenemos información útil en otras variables.
Podríamos asignarle el valor de NA a dichas observaciones con if_else() o case_when():
df_robos_cono_sur %>%
mutate(robos_c100k = case_when(
pais == "Argentina" & anio <= 2008 ~ NA,
TRUE ~ robos_c100k
))Lo anterior falla, pese a que la sintaxis de case_when() es correcta! El problema es que cuando creamos valores perdidos debemos decirle explícitamente a R qué tipo de NAs utilizaremos, según el tipo de vector. Los tipos más comunes son NA_character_ (para vectores de caracteres, chr) o NA_real_ (para vectores de números reales, dbl). Veamos cómo ahora funcionará:
df_robos_cono_sur %>%
mutate(robos_c100k = case_when(
pais == "Argentina" & anio <= 2008 ~ NA_real_,
TRUE ~ robos_c100k
))## # A tibble: 33 x 4
## pais pais_codigo anio robos_c100k
## <chr> <chr> <dbl> <dbl>
## 1 Argentina ARG 2006 NA
## 2 Argentina ARG 2007 NA
## 3 Argentina ARG 2008 NA
## 4 Argentina ARG 2009 NA
## 5 Argentina ARG 2010 NA
## 6 Argentina ARG 2011 NA
## 7 Argentina ARG 2012 NA
## 8 Argentina ARG 2013 NA
## 9 Argentina ARG 2014 668.
## 10 Argentina ARG 2015 626.
## # ... with 23 more rowsUnir bases de datos
Aquí tenemos una base con muchos datos de los World Development Indicators del Banco Mundial. Están para los tres países del Cono Sur, pero desde 2007 a 2016 (falta 2006, en comparación a los datos anteriores).
## Parsed with column specification:
## cols(
## .default = col_double(),
## pais_codigo = col_character(),
## external_debt_stocks_total_dod_current_us = col_logical(),
## total_debt_service_percent_of_exports_of_goods_services_and_primary_income = col_logical()
## )## See spec(...) for full column specifications.## # A tibble: 30 x 57
## pais_codigo anio population_total population_grow~ surface_area_sq~ population_dens~ poverty_headcou~ poverty_headcou~ gni_atlas_metho~ gni_per_capita_~ gni_ppp_current~ gni_per_capita_~ income_share_he~ life_expectancy~ fertility_rate_~
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ARG 2007 39684295 0.999 2780400 14.5 NA 2.9 258429317135. 6510 656745628034. 16550 3.9 74.8 2.38
## 2 CHL 2007 16530195 1.07 756096. 22.2 NA NA 143603828921. 8690 248814945028. 15050 NA 78.1 1.90
## 3 URY 2007 3331749 0.191 176220 19.0 29.6 0.3 21283077870. 6390 44113794683. 13240 4.8 76.3 2.05
## 4 ARG 2008 40080160 0.993 2780400 14.6 NA 2.6 307363845739. 7670 697740913973. 17410 4 75.0 2.37
## 5 CHL 2008 16708258 1.07 756096. 22.5 NA NA 167969056839. 10050 254260262605. 15220 NA 78.3 1.90
## 6 URY 2008 3340221 0.254 176220 19.1 24.2 0.2 25752230257. 7710 47817999408. 14320 5 76.4 2.03
## 7 ARG 2009 40482788 1.00 2780400 14.8 NA 2.6 315586430026. 7800 657382734891. 16240 4 75.1 2.36
## 8 CHL 2009 16886186 1.06 756096. 22.7 25.3 2.6 168009833889. 9950 254255791261. 15060 4.6 78.6 1.89
## 9 URY 2009 3349676 0.283 176220 19.1 21 0.2 29494248573. 8810 50075569089. 14950 4.8 76.6 2.02
## 10 ARG 2010 40788453 0.752 2780400 14.9 NA 1.1 378241273936. 9270 729853440301. 17890 4.6 75.3 2.35
## # ... with 20 more rows, and 42 more variables: adolescent_fertility_rate_births_per_1_000_women_ages_15_19 <dbl>, contraceptive_prevalence_any_methods_percent_of_women_ages_15_49 <dbl>,
## # births_attended_by_skilled_health_staff_percent_of_total <dbl>, mortality_rate_under_5_per_1_000_live_births <dbl>, prevalence_of_underweight_weight_for_age_percent_of_children_under_5 <dbl>,
## # immunization_measles_percent_of_children_ages_12_23_months <dbl>, primary_completion_rate_total_percent_of_relevant_age_group <dbl>, school_enrollment_primary_percent_gross <dbl>, school_enrollment_secondary_percent_gross <dbl>,
## # school_enrollment_primary_and_secondary_gross_gender_parity_index_gpi <dbl>, prevalence_of_hiv_total_percent_of_population_ages_15_49 <dbl>, forest_area_sq_km <dbl>, terrestrial_and_marine_protected_areas_percent_of_total_territorial_area <dbl>,
## # annual_freshwater_withdrawals_total_percent_of_internal_resources <dbl>, urban_population_growth_annual_percent <dbl>, energy_use_kg_of_oil_equivalent_per_capita <dbl>, co2_emissions_metric_tons_per_capita <dbl>,
## # electric_power_consumption_k_wh_per_capita <dbl>, gdp_current_us <dbl>, gdp_growth_annual_percent <dbl>, inflation_gdp_deflator_annual_percent <dbl>, agriculture_forestry_and_fishing_value_added_percent_of_gdp <dbl>,
## # industry_including_construction_value_added_percent_of_gdp <dbl>, exports_of_goods_and_services_percent_of_gdp <dbl>, imports_of_goods_and_services_percent_of_gdp <dbl>, gross_capital_formation_percent_of_gdp <dbl>,
## # revenue_excluding_grants_percent_of_gdp <dbl>, time_required_to_start_a_business_days <dbl>, domestic_credit_provided_by_financial_sector_percent_of_gdp <dbl>, tax_revenue_percent_of_gdp <dbl>, military_expenditure_percent_of_gdp <dbl>,
## # mobile_cellular_subscriptions_per_100_people <dbl>, high_technology_exports_percent_of_manufactured_exports <dbl>, statistical_capacity_score_overall_average <dbl>, merchandise_trade_percent_of_gdp <dbl>,
## # net_barter_terms_of_trade_index_2000_100 <dbl>, external_debt_stocks_total_dod_current_us <lgl>, total_debt_service_percent_of_exports_of_goods_services_and_primary_income <lgl>, net_migration <dbl>,
## # personal_remittances_received_current_us <dbl>, foreign_direct_investment_net_inflows_bo_p_current_us <dbl>, net_official_development_assistance_and_official_aid_received_current_us <dbl>¿Cómo podemos añadir toda esta nueva información a nuestra base original? No podemos simplemente pegar las columnas unas al lado de otras con bind_cols() (los números de filas son distintos, lo mismo con el orden de las observaciones).
Lo mejor es realizar una unión de bases (merge/join). Lejos la más común de estas operaciones es la unión izquierda, en la que queremos añadir información a una base (la izquierda) a partir de otra (la derecha). left_join() nos permitirá hacer esto, mirando las observaciones de ambas bases donde las columnas de identificación toman los mismos valores:
df_robos_cono_sur_con_wdi <- left_join(
x = df_robos_cono_sur, y = df_wdi,
by = c("pais_codigo", "anio") # by dice cuáles son las variables de id.
)
df_robos_cono_sur_con_wdi## # A tibble: 33 x 59
## pais pais_codigo anio robos_c100k population_total population_grow~ surface_area_sq~ population_dens~ poverty_headcou~ poverty_headcou~ gni_atlas_metho~ gni_per_capita_~ gni_ppp_current~ gni_per_capita_~ income_share_he~ life_expectancy~
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Arge~ ARG 2006 738. NA NA NA NA NA NA NA NA NA NA NA NA
## 2 Arge~ ARG 2007 662. 39684295 0.999 2780400 14.5 NA 2.9 258429317135. 6510 656745628034. 16550 3.9 74.8
## 3 Arge~ ARG 2008 704. 40080160 0.993 2780400 14.6 NA 2.6 307363845739. 7670 697740913973. 17410 4 75.0
## 4 Arge~ ARG 2009 NA 40482788 1.00 2780400 14.8 NA 2.6 315586430026. 7800 657382734891. 16240 4 75.1
## 5 Arge~ ARG 2010 NA 40788453 0.752 2780400 14.9 NA 1.1 378241273936. 9270 729853440301. 17890 4.6 75.3
## 6 Arge~ ARG 2011 NA 41261490 1.15 2780400 15.1 NA 0.9 442037545216. 10710 794325172722. 19250 4.8 75.4
## 7 Arge~ ARG 2012 NA 41733271 1.14 2780400 15.2 NA 0.8 496046283910. 11890 805324243205. 19300 4.9 75.6
## 8 Arge~ ARG 2013 NA 42202935 1.12 2780400 15.4 NA 0.8 543285805981. 12870 841055034261. 19930 5 75.8
## 9 Arge~ ARG 2014 668. 42669500 1.10 2780400 15.6 NA 0.7 526784533342. 12350 836246704582. 19600 5.1 75.9
## 10 Arge~ ARG 2015 626. 43131966 1.08 2780400 15.8 NA NA 543279945585. 12600 869846606665. 20170 NA 76.1
## # ... with 23 more rows, and 43 more variables: fertility_rate_total_births_per_woman <dbl>, adolescent_fertility_rate_births_per_1_000_women_ages_15_19 <dbl>, contraceptive_prevalence_any_methods_percent_of_women_ages_15_49 <dbl>,
## # births_attended_by_skilled_health_staff_percent_of_total <dbl>, mortality_rate_under_5_per_1_000_live_births <dbl>, prevalence_of_underweight_weight_for_age_percent_of_children_under_5 <dbl>,
## # immunization_measles_percent_of_children_ages_12_23_months <dbl>, primary_completion_rate_total_percent_of_relevant_age_group <dbl>, school_enrollment_primary_percent_gross <dbl>, school_enrollment_secondary_percent_gross <dbl>,
## # school_enrollment_primary_and_secondary_gross_gender_parity_index_gpi <dbl>, prevalence_of_hiv_total_percent_of_population_ages_15_49 <dbl>, forest_area_sq_km <dbl>, terrestrial_and_marine_protected_areas_percent_of_total_territorial_area <dbl>,
## # annual_freshwater_withdrawals_total_percent_of_internal_resources <dbl>, urban_population_growth_annual_percent <dbl>, energy_use_kg_of_oil_equivalent_per_capita <dbl>, co2_emissions_metric_tons_per_capita <dbl>,
## # electric_power_consumption_k_wh_per_capita <dbl>, gdp_current_us <dbl>, gdp_growth_annual_percent <dbl>, inflation_gdp_deflator_annual_percent <dbl>, agriculture_forestry_and_fishing_value_added_percent_of_gdp <dbl>,
## # industry_including_construction_value_added_percent_of_gdp <dbl>, exports_of_goods_and_services_percent_of_gdp <dbl>, imports_of_goods_and_services_percent_of_gdp <dbl>, gross_capital_formation_percent_of_gdp <dbl>,
## # revenue_excluding_grants_percent_of_gdp <dbl>, time_required_to_start_a_business_days <dbl>, domestic_credit_provided_by_financial_sector_percent_of_gdp <dbl>, tax_revenue_percent_of_gdp <dbl>, military_expenditure_percent_of_gdp <dbl>,
## # mobile_cellular_subscriptions_per_100_people <dbl>, high_technology_exports_percent_of_manufactured_exports <dbl>, statistical_capacity_score_overall_average <dbl>, merchandise_trade_percent_of_gdp <dbl>,
## # net_barter_terms_of_trade_index_2000_100 <dbl>, external_debt_stocks_total_dod_current_us <lgl>, total_debt_service_percent_of_exports_of_goods_services_and_primary_income <lgl>, net_migration <dbl>,
## # personal_remittances_received_current_us <dbl>, foreign_direct_investment_net_inflows_bo_p_current_us <dbl>, net_official_development_assistance_and_official_aid_received_current_us <dbl>