02A - Manejo de datos
Si quieres correr este script localmente, acá puedes descargar el proyecto comprimido en .zip. Paquetes que necesitas tener instalados antes de comenzar con el proyecto (2A, 2B, 2C):
tidyverse,janitor,writexl.
Repaso de la clase pasada: R Markdown
- R Markdown interpreta texto plano y generara documentos a partir de este.
- Estos documentos pueden ser reportes, presentaciones, papers, pósters, CVs, etc. [ejs. de plantillas]
- La interpretación requiere precisión en la sintaxis. Por defecto, R Markdown interpreta todo como texto, a menos que tenga una sintaxis especial.
- Una forma especial de sintaxis, por ejemplo, es
 - Revisemos la sintaxis en el “torpedo” de R Markdown.
- Una forma especial de sintaxis, por ejemplo, es
Manejo de bases de datos
Manejo de datos = limpiar y ordenar datos para poder analizarlos.
Se suele decir que el 80% del análisis de datos es solo manejo (Wickham, 2014).
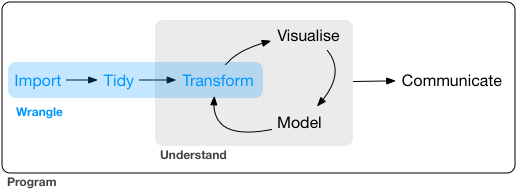
Fuente: Grolemund & Wickham, 2017
Partes de una base de datos tabular

- Encabezado (header)
- Fila (row)
- Columna (column)
- Celda (cell)
Una pequeña mnemotecnia:
La base de datos ideal: tidy
- En el paradigma “tidy” (Wickham, 2014):
- Cada variable es una columna
- Cada observación es una fila
- Cada valor es una celda
- Existe una base de datos para cada unidad observacional

(Ejercicio A)
- Por favor revisar este link.
- Contiene un panel para las emisiones anuales de CO2 de los países americanos (unidad de medida: toneladas per capita).
- Hay tres bases con la misma información, una por cada hoja. ¿Cuál es la “tidy”?
Operaciones básicas en bases de datos (Wickham, 2014)
- Transformar columnas (añadir o modificar existentes)
- Puede ser en una sola columna o en múltiples columnas
- En el tidyverse,
mutate()
- Seleccionar columnas (y excluir otras)
- En el tidyverse,
select()
- En el tidyverse,
- Filtrar observaciones en base a una condición
- En el tidyverse,
filter()
- En el tidyverse,
- Ordenar la base de datos, en base a una(s) variable(s)
- En el tidyverse,
arrange()
- En el tidyverse,
- Agregar/colapsar la base de datos
- Colapsar múltiples valores en algún resumen (por ejemplo, media o suma)
- Puede ser para toda la base o por subgrupos
- En el tidyverse,
summarize()
(Ejercicio B)
Favor ir a este link
¿Qué operaciones básicas pueden ser interesantes para comenzar a analizar estos datos? Contesta con dos ejemplos:
Trabajo con R
Comenzaremos cargando el tidyverse:
Base de datos: aprobación de presidentes/as en Latinoamérica
Tenemos una base de datos ligeramente editada a partir de Reyes-Housholder (2019).
- Incluye también un par de variables de los World Development Indicators, recopiladas por Quality of Government.
La base de datos se encuentra en
datos/base_aprob_reyes-housholder.csv.Contiene información de la aprobación de presidentes/as en 17 países de América Latina por trimestre (2000-2014), además de variables de control.
- ¿Cuál es la unidad de análisis de la base? ¿Cuántas observaciones tendrá, asumiendo un panel balanceado?
Carga de base en formato csv
## Parsed with column specification:
## cols(
## country = col_character(),
## year = col_double(),
## quarter = col_double(),
## president = col_character(),
## net_approval = col_double(),
## pres_sex = col_character(),
## pres_sex_d = col_double(),
## exec_corr = col_double(),
## gdp_growth = col_double(),
## unemp = col_double(),
## wdi_gdp = col_double(),
## wdi_pop = col_double()
## )Resúmenes simples para data frames
El resumen más simple de un objeto en R suele poder obtenerse con su nombre comando. Nota cómo debajo de cada nombre, algunas variables tienen <dbl> y otras <chr>. ¿Qué significa esto?
## # A tibble: 1,020 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370
## # ... with 1,010 more rowsPor cierto, podemos obtener un resumen similar clickeando nuestro objeto en el panel “Environment” (superior derecho) de RStudio. Esto es lo mismo que ocupar el comando View():
Otro resumen útil es la función glimpse() del tidyverse, que nos da otra perspectiva:
## Rows: 1,020
## Columns: 12
## $ country <chr> "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Ar...
## $ year <dbl> 2000, 2000, 2000, 2000, 2001, 2001, 2001, 2001, 2002, 2002, 2002, 2002, 2003, 2003, 2003, 2003, 2004, 2004, 2004, 2004, 2005, 2005, 2005, 2005, 2006, 2006, 2006, 2006, 2007, 2007, 2007, 2007, 2008, 2008, 2008, 2008, 2009, 20...
## $ quarter <dbl> 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3,...
## $ president <chr> "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Eduardo Alberto Duhalde", "Eduardo Alberto Duha...
## $ net_approval <dbl> 40.126, 16.390, 23.968, -18.254, -6.973, -20.082, -19.384, -23.182, -2.006, -20.075, -24.965, -16.831, -2.775, 26.511, 53.679, 52.975, 57.142, 52.756, 39.078, 44.899, 45.691, 45.429, 40.584, 43.390, 48.887, 46.757, 44.563, 4...
## $ pres_sex <chr> "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", ...
## $ pres_sex_d <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ exec_corr <dbl> 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 25.00388, 25.00388, 25.00388, 25.00388, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.1...
## $ gdp_growth <dbl> -0.800000, -0.800000, -0.800000, -0.800000, -4.400000, -4.400000, -4.400000, -4.400000, -10.900000, -10.900000, -10.900000, -10.900000, 8.800000, 8.800000, 8.800000, 8.800000, 9.000000, 9.000000, 9.000000, 9.000000, 8.900000...
## $ unemp <dbl> 15.0000, 15.0000, 15.0000, 15.0000, 18.3000, 18.3000, 18.3000, 18.3000, 17.9000, 17.9000, 17.9000, 17.9000, 19.9500, 17.4400, 16.1318, 14.4528, 14.2935, 14.6621, 13.1475, 11.9976, 12.9295, 11.9526, 11.1434, 10.0284, 11.3064,...
## $ wdi_gdp <dbl> 552151219031, 552151219031, 552151219031, 552151219031, 527807756979, 527807756979, 527807756979, 527807756979, 470305820970, 470305820970, 470305820970, 470305820970, 511866938234, 511866938234, 511866938234, 511866938234, ...
## $ wdi_pop <dbl> 37057452, 37057452, 37057452, 37057452, 37471509, 37471509, 37471509, 37471509, 37889370, 37889370, 37889370, 37889370, 38309379, 38309379, 38309379, 38309379, 38728696, 38728696, 38728696, 38728696, 39145488, 39145488, 3914...¿Qué significan las variables de esta base de datos? Completa la siguiente tabla:
| Variable | Descripción |
|---|---|
| country | País. |
| year | Año. |
| quarter | Trimestre. |
| president | Presidente/a. |
| net_approval | Aprobación neta del presidente/a (% aprobación - % rechazo). |
| pres_sex | |
| pres_sex_d | |
| exec_corr | Corrupción en el Ejecutivo, según V-Dem. De 0 a 100 (mayor es más corrupción). |
| gdp_growth | |
| unemp | |
| wdi_gdp | Producto interno bruto del país, ajustado por paridad de cambio (PPP) y constante en dólares del 2011. |
| wdi_pop |
Manejo de datos: operaciones básicas
En todas las operaciones básicas que veremos hoy el primer argumento en la función será el data frame a editar.
Seleccionar columnas con select()
Seleccionemos solo la columna de países:
## # A tibble: 1,020 x 1
## country
## <chr>
## 1 Argentina
## 2 Argentina
## 3 Argentina
## 4 Argentina
## 5 Argentina
## 6 Argentina
## 7 Argentina
## 8 Argentina
## 9 Argentina
## 10 Argentina
## # ... with 1,010 more rowsRecuerda que esto no creó ningún objeto nuevo, es solo un comando que estamos ejecutando en la consola. Si quisiéramos crear un objeto nuevo, tendríamos que asignarlo:
## # A tibble: 1,020 x 1
## country
## <chr>
## 1 Argentina
## 2 Argentina
## 3 Argentina
## 4 Argentina
## 5 Argentina
## 6 Argentina
## 7 Argentina
## 8 Argentina
## 9 Argentina
## 10 Argentina
## # ... with 1,010 more rowsPodemos seleccionar múltiples columnas a la vez, separadas por comas:
## # A tibble: 1,020 x 3
## country year unemp
## <chr> <dbl> <dbl>
## 1 Argentina 2000 15
## 2 Argentina 2000 15
## 3 Argentina 2000 15
## 4 Argentina 2000 15
## 5 Argentina 2001 18.3
## 6 Argentina 2001 18.3
## 7 Argentina 2001 18.3
## 8 Argentina 2001 18.3
## 9 Argentina 2002 17.9
## 10 Argentina 2002 17.9
## # ... with 1,010 more rowsSupongamos que queremos las primeras cinco variables de la base de datos. Las siguientes tres formas nos permitirán obtenerlas:
## # A tibble: 1,020 x 5
## country year quarter president net_approval
## <chr> <dbl> <dbl> <chr> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1
## 2 Argentina 2000 2 Fernando de la Rúa 16.4
## 3 Argentina 2000 3 Fernando de la Rúa 24.0
## 4 Argentina 2000 4 Fernando de la Rúa -18.3
## 5 Argentina 2001 1 Fernando de la Rúa -6.97
## 6 Argentina 2001 2 Fernando de la Rúa -20.1
## 7 Argentina 2001 3 Fernando de la Rúa -19.4
## 8 Argentina 2001 4 Fernando de la Rúa -23.2
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1
## # ... with 1,010 more rows## # A tibble: 1,020 x 5
## country year quarter president net_approval
## <chr> <dbl> <dbl> <chr> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1
## 2 Argentina 2000 2 Fernando de la Rúa 16.4
## 3 Argentina 2000 3 Fernando de la Rúa 24.0
## 4 Argentina 2000 4 Fernando de la Rúa -18.3
## 5 Argentina 2001 1 Fernando de la Rúa -6.97
## 6 Argentina 2001 2 Fernando de la Rúa -20.1
## 7 Argentina 2001 3 Fernando de la Rúa -19.4
## 8 Argentina 2001 4 Fernando de la Rúa -23.2
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1
## # ... with 1,010 more rows## # A tibble: 1,020 x 5
## country year quarter president net_approval
## <chr> <dbl> <dbl> <chr> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1
## 2 Argentina 2000 2 Fernando de la Rúa 16.4
## 3 Argentina 2000 3 Fernando de la Rúa 24.0
## 4 Argentina 2000 4 Fernando de la Rúa -18.3
## 5 Argentina 2001 1 Fernando de la Rúa -6.97
## 6 Argentina 2001 2 Fernando de la Rúa -20.1
## 7 Argentina 2001 3 Fernando de la Rúa -19.4
## 8 Argentina 2001 4 Fernando de la Rúa -23.2
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1
## # ... with 1,010 more rowsEl comando select() también nos sirve para reordenar las columnas. Supongamos que queremos que la variable president sea la primera. Podemos hacer algo como esto:
## # A tibble: 1,020 x 9
## president country year net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp
## <chr> <chr> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Fernando de la Rúa Argentina 2000 40.1 male 0 14.0 -0.8 15
## 2 Fernando de la Rúa Argentina 2000 16.4 male 0 14.0 -0.8 15
## 3 Fernando de la Rúa Argentina 2000 24.0 male 0 14.0 -0.8 15
## 4 Fernando de la Rúa Argentina 2000 -18.3 male 0 14.0 -0.8 15
## 5 Fernando de la Rúa Argentina 2001 -6.97 male 0 14.0 -4.4 18.3
## 6 Fernando de la Rúa Argentina 2001 -20.1 male 0 14.0 -4.4 18.3
## 7 Fernando de la Rúa Argentina 2001 -19.4 male 0 14.0 -4.4 18.3
## 8 Fernando de la Rúa Argentina 2001 -23.2 male 0 14.0 -4.4 18.3
## 9 Eduardo Alberto Duhalde Argentina 2002 -2.01 male 0 25.0 -10.9 17.9
## 10 Eduardo Alberto Duhalde Argentina 2002 -20.1 male 0 25.0 -10.9 17.9
## # ... with 1,010 more rowsEsta forma es un poco tediosa. Hay una función de ayuda que nos será útil en este caso, se llama everything()
## # A tibble: 1,020 x 12
## president country year quarter net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <chr> <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Fernando de la Rúa Argentina 2000 1 40.1 male 0 14.0 -0.8 15 552151219031. 37057452
## 2 Fernando de la Rúa Argentina 2000 2 16.4 male 0 14.0 -0.8 15 552151219031. 37057452
## 3 Fernando de la Rúa Argentina 2000 3 24.0 male 0 14.0 -0.8 15 552151219031. 37057452
## 4 Fernando de la Rúa Argentina 2000 4 -18.3 male 0 14.0 -0.8 15 552151219031. 37057452
## 5 Fernando de la Rúa Argentina 2001 1 -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 6 Fernando de la Rúa Argentina 2001 2 -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 7 Fernando de la Rúa Argentina 2001 3 -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 8 Fernando de la Rúa Argentina 2001 4 -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 9 Eduardo Alberto Duhalde Argentina 2002 1 -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370
## 10 Eduardo Alberto Duhalde Argentina 2002 2 -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370
## # ... with 1,010 more rowsRenombrar columnas con rename()
Podemos cambiar el nombre de una columna con el comando rename(). Por ejemplo:
## # A tibble: 1,020 x 12
## country year trimeste president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370
## # ... with 1,010 more rowsFiltrar observaciones con filter()
A menudo queremos quedarnos solo con algunas observaciones de nuestra base de datos, filtrando de acuerdo a características específicas. Podemos hacer esto gracias a la función filter() y algo llamado “operadores lógicos”. Para comenzar, quedémonos solo con las observaciones de Chile:
## # A tibble: 60 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Chile 2000 1 Eduardo Frei Ruiz-Tagle 6.22 male 0 3.63 5.3 9.2 218492826314. 15262754
## 2 Chile 2000 2 Ricardo Lagos Escobar 19.8 male 0 3.63 5.3 9.2 218492826314. 15262754
## 3 Chile 2000 3 Ricardo Lagos Escobar 19.5 male 0 3.63 5.3 9.2 218492826314. 15262754
## 4 Chile 2000 4 Ricardo Lagos Escobar 14.8 male 0 3.63 5.3 9.2 218492826314. 15262754
## 5 Chile 2001 1 Ricardo Lagos Escobar 7.99 male 0 3.63 3.3 9.1 225709747742. 15444969
## 6 Chile 2001 2 Ricardo Lagos Escobar 1.81 male 0 3.63 3.3 9.1 225709747742. 15444969
## 7 Chile 2001 3 Ricardo Lagos Escobar -1.40 male 0 3.63 3.3 9.1 225709747742. 15444969
## 8 Chile 2001 4 Ricardo Lagos Escobar 6.90 male 0 3.63 3.3 9.1 225709747742. 15444969
## 9 Chile 2002 1 Ricardo Lagos Escobar 6.60 male 0 3.63 3.1 8.9 232722483093. 15623635
## 10 Chile 2002 2 Ricardo Lagos Escobar 3.65 male 0 3.63 3.1 8.9 232722483093. 15623635
## # ... with 50 more rowsLe estamos diciendo a filter(), por medio del segundo argumento, que solo se quede con observaciones en las que la variable country es igual a Chile. Este “es igual a” es un operador lógico, que se escribe como “==” en R. Aquí hay una lista de operadores lógicos comunes:
| operador | descripción |
|---|---|
== |
es igual a |
!= |
es distinto a |
> |
es mayor a |
< |
es menor a |
>= |
es mayor o igual a |
<= |
es menor o igual a |
& |
intersección |
| |
unión |
%in% |
está contenido en |
Por ejemplo, podemos obtener todas las observaciones (país-año-trimestre) en las que la aprobación presidencial neta es positiva:
## # A tibble: 709 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452
## 4 Argentina 2003 2 Eduardo Alberto Duhalde 26.5 male 0 50.1 8.8 17.4 511866938234. 38309379
## 5 Argentina 2003 3 Néstor Carlos Kirchner 53.7 male 0 50.1 8.8 16.1 511866938234. 38309379
## 6 Argentina 2003 4 Néstor Carlos Kirchner 53.0 male 0 50.1 8.8 14.5 511866938234. 38309379
## 7 Argentina 2004 1 Néstor Carlos Kirchner 57.1 male 0 50.1 9 14.3 558086338624. 38728696
## 8 Argentina 2004 2 Néstor Carlos Kirchner 52.8 male 0 50.1 9 14.7 558086338624. 38728696
## 9 Argentina 2004 3 Néstor Carlos Kirchner 39.1 male 0 50.1 9 13.1 558086338624. 38728696
## 10 Argentina 2004 4 Néstor Carlos Kirchner 44.9 male 0 50.1 9 12.0 558086338624. 38728696
## # ... with 699 more rowsPodemos también realizar filtros más complejos. Obtengamos solo las observaciones del Cono Sur:
## # A tibble: 180 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370
## # ... with 170 more rows## # A tibble: 180 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370
## # ... with 170 more rowsPodemos también incluir pequeñas operaciones en nuestros filtros. Obtengamos todas las observaciones en las que la corrupción ejecutiva es mayor a la del promedio de toda la base:
## # A tibble: 456 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2003 1 Eduardo Alberto Duhalde -2.78 male 0 50.1 8.8 20.0 511866938234. 38309379
## 2 Argentina 2003 2 Eduardo Alberto Duhalde 26.5 male 0 50.1 8.8 17.4 511866938234. 38309379
## 3 Argentina 2003 3 Néstor Carlos Kirchner 53.7 male 0 50.1 8.8 16.1 511866938234. 38309379
## 4 Argentina 2003 4 Néstor Carlos Kirchner 53.0 male 0 50.1 8.8 14.5 511866938234. 38309379
## 5 Argentina 2004 1 Néstor Carlos Kirchner 57.1 male 0 50.1 9 14.3 558086338624. 38728696
## 6 Argentina 2004 2 Néstor Carlos Kirchner 52.8 male 0 50.1 9 14.7 558086338624. 38728696
## 7 Argentina 2004 3 Néstor Carlos Kirchner 39.1 male 0 50.1 9 13.1 558086338624. 38728696
## 8 Argentina 2004 4 Néstor Carlos Kirchner 44.9 male 0 50.1 9 12.0 558086338624. 38728696
## 9 Argentina 2005 1 Néstor Carlos Kirchner 45.7 male 0 50.1 8.9 12.9 607486243380. 39145488
## 10 Argentina 2005 2 Néstor Carlos Kirchner 45.4 male 0 50.1 8.9 12.0 607486243380. 39145488
## # ... with 446 more rows(Ejercicio C)
Selecciona solo las dos columnas que registran el sexo del presidente/a en la base de datos. Recuerda que los chunks se insertan con Ctrl/Cmd + Alt + i. Tu código:
Filtra la base de datos para que solo tenga las observaciones del año 2000. Tu código:
Filtra la base de datos para que solo incluya observaciones de crisis económica: cuando el crecimiento del PIB sea negativo y/o el desempleo sea mayor al 20%. Tu código:
Ordenar el data frame con arrange()
Podemos cambiar el orden de las observaciones con el comando arrange(). Por ejemplo, ordenémoslas desde el país-año-trimestre menos corrupto al más corrupto:
## # A tibble: 1,020 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Uruguay 2000 1 Julio Sanguietti 41.2 male 0 2.13 -1.93 13.3 42760248091. 3321245
## 2 Uruguay 2000 2 Jorge Battle 45.4 male 0 2.13 -1.93 13.3 42760248091. 3321245
## 3 Uruguay 2000 3 Jorge Battle 31.4 male 0 2.13 -1.93 13.3 42760248091. 3321245
## 4 Uruguay 2000 4 Jorge Battle 18.1 male 0 2.13 -1.93 13.3 42760248091. 3321245
## 5 Uruguay 2001 1 Jorge Battle 18.5 male 0 2.13 -3.84 14.9 41116488580. 3327103
## 6 Uruguay 2001 2 Jorge Battle 17.8 male 0 2.13 -3.84 14.9 41116488580. 3327103
## 7 Uruguay 2001 3 Jorge Battle 15.9 male 0 2.13 -3.84 14.9 41116488580. 3327103
## 8 Uruguay 2001 4 Jorge Battle 14.5 male 0 2.13 -3.84 14.9 41116488580. 3327103
## 9 Uruguay 2002 1 Jorge Battle 6.36 male 0 2.13 -7.73 16.9 37937358718. 3327773
## 10 Uruguay 2002 2 Jorge Battle -6.37 male 0 2.13 -7.73 16.9 37937358718. 3327773
## # ... with 1,010 more rowsSi quisiéramos ordenarlo inversamente, tendríamos que añadir un - (signo menos) antes de la variable:
## # A tibble: 1,020 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Venezuela 2013 1 Hugo Chávez -12.6 male 0 94.4 1.34 7.54 535572061141. 30317848
## 2 Venezuela 2013 2 Nicolás Maduro -13.7 male 0 94.4 1.34 7.54 535572061141. 30317848
## 3 Venezuela 2013 3 Nicolás Maduro -16.8 male 0 94.4 1.34 7.54 535572061141. 30317848
## 4 Venezuela 2013 4 Nicolás Maduro -16.6 male 0 94.4 1.34 7.54 535572061141. 30317848
## 5 Venezuela 2014 1 Nicolás Maduro -18.1 male 0 94.4 -3.89 6.95 514714815230. 30738378
## 6 Venezuela 2014 2 Nicolás Maduro -19.4 male 0 94.4 -3.89 6.95 514714815230. 30738378
## 7 Venezuela 2014 3 Nicolás Maduro -22.1 male 0 94.4 -3.89 6.95 514714815230. 30738378
## 8 Venezuela 2014 4 Nicolás Maduro -24.9 male 0 94.4 -3.89 6.95 514714815230. 30738378
## 9 Venezuela 2007 1 Hugo Chávez -10.2 male 0 93.5 8.75 7.47 478405261854. 27691965
## 10 Venezuela 2007 2 Hugo Chávez -11.0 male 0 93.5 8.75 7.47 478405261854. 27691965
## # ... with 1,010 more rowsPodemos ordenar por más de una variable. Esto es, ordenar a partir de una primera variable y luego ordenar los empates a partir de otra segunda variable. Veamos el siguiente ejemplo:
## # A tibble: 1,020 x 12
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Brazil 2013 1 Dilma Vana Rousseff 62.5 female 1 27.3 3 5.55 3.12e12 202408632
## 2 Brazil 2012 4 Dilma Vana Rousseff 60.9 female 1 33.4 1.9 4.93 3.03e12 200560983
## 3 Brazil 2012 2 Dilma Vana Rousseff 60.5 female 1 33.4 1.9 5.9 3.03e12 200560983
## 4 Brazil 2012 3 Dilma Vana Rousseff 58.7 female 1 33.4 1.9 5.37 3.03e12 200560983
## 5 Brazil 2012 1 Dilma Vana Rousseff 57.2 female 1 33.4 1.9 5.8 3.03e12 200560983
## 6 Brazil 2011 4 Dilma Vana Rousseff 54.3 female 1 33.4 4 5.23 2.97e12 198686688
## 7 Brazil 2011 1 Dilma Vana Rousseff 47.7 female 1 33.4 4 6.33 2.97e12 198686688
## 8 Brazil 2011 3 Dilma Vana Rousseff 45.6 female 1 33.4 4 6 2.97e12 198686688
## 9 Brazil 2013 2 Dilma Vana Rousseff 44.4 female 1 27.3 3 5.86 3.12e12 202408632
## 10 Argentina 2011 4 Cristina Fernández de Kirchner 44.3 female 1 52.4 6 6.75 8.18e11 41656879
## # ... with 1,010 more rowsTransformar variables con mutate()
Transformaciones con una variable
Supongamos que queremos crear una variable con el PIB en versión logarítmica:
## # A tibble: 1,020 x 13
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop wdi_gdp_log
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452 27.0
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452 27.0
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452 27.0
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452 27.0
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509 27.0
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509 27.0
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509 27.0
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509 27.0
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370 26.9
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370 26.9
## # ... with 1,010 more rowsPodemos realizar cualquier tipo de operación en las variables. Por ejemplo, transformemos la escala de wdi_pop a millones:
## # A tibble: 1,020 x 13
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop wdi_pop_mill
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452 37.1
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452 37.1
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452 37.1
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452 37.1
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370 37.9
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370 37.9
## # ... with 1,010 more rowsTransformaciones con múltiples variables
Crucialmente, podemos generar operaciones entre las variables. Por ejemplo, calculemos el GDP per capita:
## # A tibble: 1,020 x 13
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop wdi_gdp_pc
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370 12413.
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370 12413.
## # ... with 1,010 more rowsVarias transformaciones a la vez:
Algo como lo siguiente funcionará:
## # A tibble: 1,020 x 14
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop wdi_pop_mill wdi_gdp_pc
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452 37.1 14900.
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452 37.1 14900.
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452 37.1 14900.
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452 37.1 14900.
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5 14086.
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5 14086.
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5 14086.
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509 37.5 14086.
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370 37.9 12413.
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370 37.9 12413.
## # ... with 1,010 more rows(Ejercicio D)
Crea un nuevo data frame, que esté ordenado desde el país-año-trimeste con menor aprobación presidencial al con mayor aprobación presidencial (recuerda crear el nuevo objeto y ponerle un buen nombre!). Tu código:
En tu nuevo objeto, obtén solo con las observaciones que tengan presidentas. Tu código:
Crea una nueva variable, que registre el desempleo como proporción en vez de porcentaje. Tu código:
Agregar/colapsar con summarize() / hacer operaciones por grupos con group_by()
Podemos hacer resúmenes para la base de datos con summarize:
## # A tibble: 1 x 1
## prom_desemp
## <dbl>
## 1 7.04Como antes, podemos hacer varios a la vez:
summarize(df_aprob,
prom_desemp = mean(unemp),
prom_crec = mean(gdp_growth),
prom_aprob = mean(net_approval))## # A tibble: 1 x 3
## prom_desemp prom_crec prom_aprob
## <dbl> <dbl> <dbl>
## 1 7.04 3.77 15.3Resúmenes agrupados
Lo realmente interesante es hacer resúmenes por grupos. Primero debemos tener una versión “agrupada” de la base de datos. Esta es igual que nuestra base original, pero R sabe que las siguientes operaciones que realicemos en ella deberán ser agrupadas (veamos la ligera diferencia cuando hacemos un resumen con glimpse())
## Rows: 1,020
## Columns: 12
## Groups: country [17]
## $ country <chr> "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Argentina", "Ar...
## $ year <dbl> 2000, 2000, 2000, 2000, 2001, 2001, 2001, 2001, 2002, 2002, 2002, 2002, 2003, 2003, 2003, 2003, 2004, 2004, 2004, 2004, 2005, 2005, 2005, 2005, 2006, 2006, 2006, 2006, 2007, 2007, 2007, 2007, 2008, 2008, 2008, 2008, 2009, 20...
## $ quarter <dbl> 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3,...
## $ president <chr> "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Fernando de la Rúa", "Eduardo Alberto Duhalde", "Eduardo Alberto Duha...
## $ net_approval <dbl> 40.126, 16.390, 23.968, -18.254, -6.973, -20.082, -19.384, -23.182, -2.006, -20.075, -24.965, -16.831, -2.775, 26.511, 53.679, 52.975, 57.142, 52.756, 39.078, 44.899, 45.691, 45.429, 40.584, 43.390, 48.887, 46.757, 44.563, 4...
## $ pres_sex <chr> "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", "male", ...
## $ pres_sex_d <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...
## $ exec_corr <dbl> 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 14.01525, 25.00388, 25.00388, 25.00388, 25.00388, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.14544, 50.1...
## $ gdp_growth <dbl> -0.800000, -0.800000, -0.800000, -0.800000, -4.400000, -4.400000, -4.400000, -4.400000, -10.900000, -10.900000, -10.900000, -10.900000, 8.800000, 8.800000, 8.800000, 8.800000, 9.000000, 9.000000, 9.000000, 9.000000, 8.900000...
## $ unemp <dbl> 15.0000, 15.0000, 15.0000, 15.0000, 18.3000, 18.3000, 18.3000, 18.3000, 17.9000, 17.9000, 17.9000, 17.9000, 19.9500, 17.4400, 16.1318, 14.4528, 14.2935, 14.6621, 13.1475, 11.9976, 12.9295, 11.9526, 11.1434, 10.0284, 11.3064,...
## $ wdi_gdp <dbl> 552151219031, 552151219031, 552151219031, 552151219031, 527807756979, 527807756979, 527807756979, 527807756979, 470305820970, 470305820970, 470305820970, 470305820970, 511866938234, 511866938234, 511866938234, 511866938234, ...
## $ wdi_pop <dbl> 37057452, 37057452, 37057452, 37057452, 37471509, 37471509, 37471509, 37471509, 37889370, 37889370, 37889370, 37889370, 38309379, 38309379, 38309379, 38309379, 38728696, 38728696, 38728696, 38728696, 39145488, 39145488, 3914...Hagamos una operación de resumen en esta nueva base:
summarize(df_aprob_por_pais,
prom_desemp = mean(unemp),
prom_crec = mean(gdp_growth),
prom_aprob = mean(net_approval))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 17 x 4
## country prom_desemp prom_crec prom_aprob
## <chr> <dbl> <dbl> <dbl>
## 1 Argentina 11.0 2.72 16.7
## 2 Bolivia 3.70 4.24 11.3
## 3 Brazil 8.35 3.4 34.2
## 4 Chile 8.18 4.33 5.71
## 5 Colombia 12.5 4.35 27.1
## 6 Costa Rica 6.73 4.15 14.5
## 7 Ecuador 6.76 4.31 37.1
## 8 El Salvador 5.75 1.87 39.1
## 9 Guatemala 2.80 3.47 5.44
## 10 Honduras 4.22 4.08 12.7
## 11 Mexico 3.99 2.10 28.9
## 12 Nicaragua 6.78 3.73 16.2
## 13 Panama 8.45 6.31 14.2
## 14 Paraguay 5.69 3.66 10.9
## 15 Peru 4.32 5.30 -26.2
## 16 Uruguay 10.3 3.08 26.9
## 17 Venezuela 10.3 3.04 -14.8Hacer cadenas de operaciones con las pipes (%>%)
La mayor parte del tiempo queremos hacer más de una operación en una base de datos. Por ejemplo, podríamos querer (1) crear una nueva variable con PIB per capita, y luego (2) filtrar las observaciones con valores iguales o mayores a la media de PIB per capita en toda la base:
df_aprob_con_pib_pc <- mutate(df_aprob, pib_pc = wdi_gdp / wdi_pop)
filter(df_aprob_con_pib_pc, pib_pc > mean(pib_pc))## # A tibble: 492 x 13
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop pib_pc
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370 12413.
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370 12413.
## # ... with 482 more rowsEsta misma cadena de operaciones se puede escribir de la siguiente forma:
## # A tibble: 492 x 13
## country year quarter president net_approval pres_sex pres_sex_d exec_corr gdp_growth unemp wdi_gdp wdi_pop pib_pc
## <chr> <dbl> <dbl> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Argentina 2000 1 Fernando de la Rúa 40.1 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 2 Argentina 2000 2 Fernando de la Rúa 16.4 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 3 Argentina 2000 3 Fernando de la Rúa 24.0 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 4 Argentina 2000 4 Fernando de la Rúa -18.3 male 0 14.0 -0.8 15 552151219031. 37057452 14900.
## 5 Argentina 2001 1 Fernando de la Rúa -6.97 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 6 Argentina 2001 2 Fernando de la Rúa -20.1 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 7 Argentina 2001 3 Fernando de la Rúa -19.4 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 8 Argentina 2001 4 Fernando de la Rúa -23.2 male 0 14.0 -4.4 18.3 527807756979. 37471509 14086.
## 9 Argentina 2002 1 Eduardo Alberto Duhalde -2.01 male 0 25.0 -10.9 17.9 470305820970. 37889370 12413.
## 10 Argentina 2002 2 Eduardo Alberto Duhalde -20.1 male 0 25.0 -10.9 17.9 470305820970. 37889370 12413.
## # ... with 482 more rows¡Este código es sorprendemente legible! Las pipes (%>%) se leen como “luego” (o “pero luego”) y se insertan con Ctrl/Cmd + Shift + M en RStudio. Pueden ver todos los atajos de teclado en Help > Keyboard Shortcuts Help.
Uno de los usos más comunes de las pipes es el combo group_by() + summarize(). Repitamos nuestras operaciones de antes para hacer un resumen agrupado:
df_aprob %>%
group_by(country) %>%
summarize(prom_desemp = mean(unemp),
prom_crec = mean(gdp_growth),
prom_aprob = mean(net_approval))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 17 x 4
## country prom_desemp prom_crec prom_aprob
## <chr> <dbl> <dbl> <dbl>
## 1 Argentina 11.0 2.72 16.7
## 2 Bolivia 3.70 4.24 11.3
## 3 Brazil 8.35 3.4 34.2
## 4 Chile 8.18 4.33 5.71
## 5 Colombia 12.5 4.35 27.1
## 6 Costa Rica 6.73 4.15 14.5
## 7 Ecuador 6.76 4.31 37.1
## 8 El Salvador 5.75 1.87 39.1
## 9 Guatemala 2.80 3.47 5.44
## 10 Honduras 4.22 4.08 12.7
## 11 Mexico 3.99 2.10 28.9
## 12 Nicaragua 6.78 3.73 16.2
## 13 Panama 8.45 6.31 14.2
## 14 Paraguay 5.69 3.66 10.9
## 15 Peru 4.32 5.30 -26.2
## 16 Uruguay 10.3 3.08 26.9
## 17 Venezuela 10.3 3.04 -14.8(Ejercicios E-G)
E. Calcula, ayudándote de las pipes, la mediana por país de corrupción ejecutiva y PIB. Recuerda que puedes insertar chunks con Ctrl/Cmd + Alt + i y pipes con Ctrl/Cmd + Shift + M. Tu código:
F. De nuevo usando pipes, ordena los países en la base desde el que tuvo el mayor PIB per cápita promedio en el período 2010-2014 hasta el que tuvo el menor. Tu código:
G. ¿Qué país-año-trimestre, entre los gobernados por mujeres, tuvo la corrupción ejecutiva más alta? ¿Y la aprobación neta más alta?