04 - Guía búsqueda de ayuda
En esta guía vamos a revisar algunos tips y recursos para buscar ayuda efectivamente, en el contexto de proyectos de análisis de datos.
Leer archivos de ayuda de R
Todas las funciones en R tienen un archivo de ayuda asociado. Podemos acceder a estos simplemente antecediendo el nombre de la función con un signo de interrogación:
?mean
?`%>%` # con estos tildes invertidos podemos ingresar funciones que tengan caracteres especiales
?`%in%`Podemos leer un archivo de ayuda de R de la siguiente forma:
.](imgs/trad-help-files.png)
Figure 1: Traducido de Healy (2018).
Encontrar funciones en línea
CRAN packages
CRAN es el sitio de los repositorios oficiales de R. La página web es un poco confusa, pero usualmente encontramos los paquetes que queremos buscando en Google cran <paquete>. Por ejemplo, este es el sitio para el paquete dplyr.
Contiene información útil sobre el paquete. Tres campos muy importantes a mirar son (a) “URL”, que nos lleva al sitio oficial del paquete, usualmente en la página del autor/a, (B) “Vignettes”, que son pequeñas guías oficiales de cómo usarlo y (C) “Reference manual”, un manual con todos los archivos de ayuda de sus funciones.
rdocumentation.org
En este sitio podemos buscar funciones y mirar sus archivos de ayuda en línea. Prueba a buscar alguna función conocida (por ejemplo, mutate, arrange, select, etc.). En la columna de la derecha aparecerán las funciones, mientras que la de la izquierda mostrará paquetes relacionados con nuestra búsqueda.
CRAN Task Views
CRAN Task Views son guías muy completas sobre qué paquetes nos pueden ayudar a lidiar con tópicos específicos. Por ejemplo, veamos el CTV de “Estadística para las Ciencias Sociales”.
Solucionar problemas
Problemas con paréntesis y comas
Vamos a usar una base de ejemplo de ggplot2, llamada midwest. Contiene información demográfica sobre distintos condados en Estados Unidos, parte de la zona geográfica llamada “Midwest”.
## # A tibble: 437 x 28
## PID county state area poptotal popdensity popwhite popblack popamerindian popasian popother percwhite percblack percamerindan percasian percother popadults perchsd percollege percprof poppovertyknown percpovertyknown percbelowpoverty
## <int> <chr> <chr> <dbl> <int> <dbl> <int> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 561 ADAMS IL 0.052 66090 1271. 63917 1702 98 249 124 96.7 2.58 0.148 0.377 0.188 43298 75.1 19.6 4.36 63628 96.3 13.2
## 2 562 ALEXA~ IL 0.014 10626 759 7054 3496 19 48 9 66.4 32.9 0.179 0.452 0.0847 6724 59.7 11.2 2.87 10529 99.1 32.2
## 3 563 BOND IL 0.022 14991 681. 14477 429 35 16 34 96.6 2.86 0.233 0.107 0.227 9669 69.3 17.0 4.49 14235 95.0 12.1
## 4 564 BOONE IL 0.017 30806 1812. 29344 127 46 150 1139 95.3 0.412 0.149 0.487 3.70 19272 75.5 17.3 4.20 30337 98.5 7.21
## 5 565 BROWN IL 0.018 5836 324. 5264 547 14 5 6 90.2 9.37 0.240 0.0857 0.103 3979 68.9 14.5 3.37 4815 82.5 13.5
## 6 566 BUREAU IL 0.05 35688 714. 35157 50 65 195 221 98.5 0.140 0.182 0.546 0.619 23444 76.6 18.9 3.28 35107 98.4 10.4
## 7 567 CALHO~ IL 0.017 5322 313. 5298 1 8 15 0 99.5 0.0188 0.150 0.282 0 3583 62.8 11.9 3.21 5241 98.5 15.1
## 8 568 CARRO~ IL 0.027 16805 622. 16519 111 30 61 84 98.3 0.661 0.179 0.363 0.500 11323 76.0 16.2 3.06 16455 97.9 11.7
## 9 569 CASS IL 0.024 13437 560. 13384 16 8 23 6 99.6 0.119 0.0595 0.171 0.0447 8825 72.3 14.1 3.21 13081 97.4 13.9
## 10 570 CHAMP~ IL 0.058 173025 2983. 146506 16559 331 8033 1596 84.7 9.57 0.191 4.64 0.922 95971 87.5 41.3 17.8 154934 89.5 15.6
## # ... with 427 more rows, and 5 more variables: percchildbelowpovert <dbl>, percadultpoverty <dbl>, percelderlypoverty <dbl>, inmetro <int>, category <chr>Generemos un gráfico con ella:
ggplot(data = midwest,
mapping = aes(x = as.factor(inmetro), y = percbelowpoverty)) +
geom_boxplot() +
labs(title = "Relación entre carácter metropolitano y pobreza en los condados del Midwest",
caption = "Fuente: Wickham (2018)",
x = "Carácter metropolitano", y = "Porcentaje de pobreza")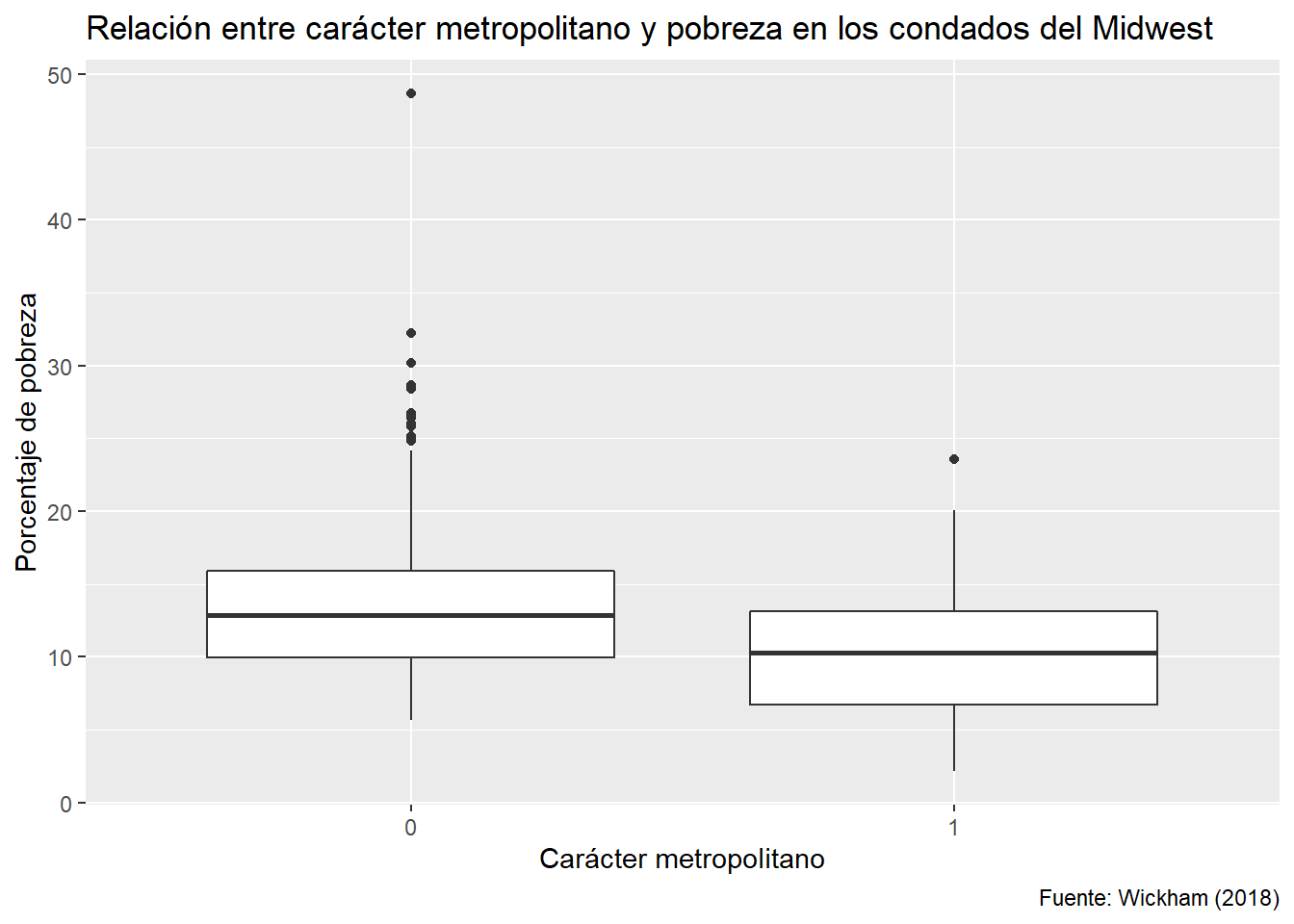
La gran mayoría de los errores que se cometen en R tienen que ver con sintaxis. Como hemos visto, R (como cualquier lenguaje de programación) espera instrucciones muy precisas de nuestra parte. Aquí algunos tips para detectar problemas de este tipo:
- Revisar dónde abren/cierran paréntesis sospechosos. Si ponemos el teclado al lado de uno de ellos, RStudio resaltará el paréntesis par a este:

Con respecto a las comas, debemos recordar que se utilizan para separar argumentos de funciones, por lo que siempre deben estar adentro de ellas. Fíjate en los argumentos de la función
labs()en el código de arriba.Otro error de sintaxis es dejar cadenas de código (
%>%o+) abiertas. Esto es, dejar un pipe o “+” extra al final. R seguirá esperando la continuación de la cadena!Un truco para ver dónde está fallando nuestro código es “ponerle sangría” línea a línea. Si tenemos un código desordenado, podemos ir ordenándolo línea a línea con Ctrl + I. Probablemente esto nos dé una mejor perspectiva para encontrar errores de comas, pipes, etc:

Leer los mensajes de error de R
Veamos el siguiente error, cuando intentamos filtrar solo los condados de Illinois en la base de ejemplo:
## Error: Problem with `filter()` input `..1`.
## x Input `..1` is named.
## i This usually means that you've used `=` instead of `==`.
## i Did you mean `state == "IL"`?¿Cuál es la solución al problema? En este caso el mensaje de error es muy claro, teníamos que usar el operador lógico ==, en vez de solo =.
Buscar en internet
La mayoría de la veces, los errores que devuelve R son difíciles de entender, a diferencia del ejemplo anterior. Una buena idea es buscar el error en Google (la mayoría de los errores ya han sido preguntados en línea), acompañado de la función y/o paquete.
Para hacer estas búsquedas eficientemente, deberíamos eliminar cualquier información del error que sea específica de nuestra base de datos (“generalizándolo”). Por ejemplo, una buena búsqueda para el error anterior podría ser la siguiente. También eliminamos símbolos especiales (como ==), que seguramente Google no tomará en cuenta.
r dplyr filter must not be named, do you need
En Google podemos poner una palabra o frase entre comillas para que los resultados deban necesariamente contenerla tal como está escrita. Podríamos buscar algo como esto:
r dplyr filter “must not be named, do you need”
Por lejos, los mejores resultados vienen de StackOverflow, un sitio web de preguntas y respuestas de programación. En Google a menudo querrán clickear en “Más resultados de stackoverflow.com”, si es que no encuentran la solución en los primeros resultados. Podemos hacer nuestra búsqueda anterior directamente en StackOverflow a través de Google, de la siguiente forma:
site:stackoverflow.com dplyr filter “must not be named, do you need”
Pedir ayuda con ejemplos reproducibles (reprex)
Cuando tenemos un problema y queremos compartirlo con alguien (colegas, StackOverflow, etc.), lo ideal es que generemos un ejemplo mínimo que reproduzca nuestro problema (reprex).
La idea es que la otra persona no tenga que lidiar con todo nuestro código, sino que solo con la parte que nos está dando problemas.
Adicionalmente, no queremos que esa otra persona tenga que entender nuestra base de datos en particular, por lo que los reprex usualmente están hechos con bases de datos pequeñas creadas o con bases de datos que vienen por defecto con R o el tidyverse (
mtcars,midwest,mpg,diamonds, etc.).Por último, queremos que esa otra persona pueda correr rápidamente nuestro código, sin tener que preocuparse de nada más aparte de nuestro problema.
Nuestro problema de antes:
## Error: Problem with `filter()` input `..1`.
## x Input `..1` is named.
## i This usually means that you've used `=` instead of `==`.
## i Did you mean `state == "IL"`?Utilizar la base “midwest” está bien, pero vamos a generar nuestro reprex con otra de ejemplo en el paquete ggplot2, llamada mpg. Esta base se ve de la siguiente forma. No importa mucho su contenido, pero sí que tenemos variables categóricas por las que querríamos filtrar, como por ejemplo “model”.
## # A tibble: 234 x 11
## manufacturer model displ year cyl trans drv cty hwy fl class
## <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
## 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
## 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
## 3 audi a4 2 2008 4 manual(m6) f 20 31 p compact
## 4 audi a4 2 2008 4 auto(av) f 21 30 p compact
## 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
## 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact
## 7 audi a4 3.1 2008 6 auto(av) f 18 27 p compact
## 8 audi a4 quattro 1.8 1999 4 manual(m5) 4 18 26 p compact
## 9 audi a4 quattro 1.8 1999 4 auto(l5) 4 16 25 p compact
## 10 audi a4 quattro 2 2008 4 manual(m6) 4 20 28 p compact
## # ... with 224 more rowsDebemos pensar hacer la misma operación con la nueva base, y que nos dé el mismo error. Además, el reprex debe incluir la carga de paquetes: